【代码拆解】Trajectory Transformer

模型结构:
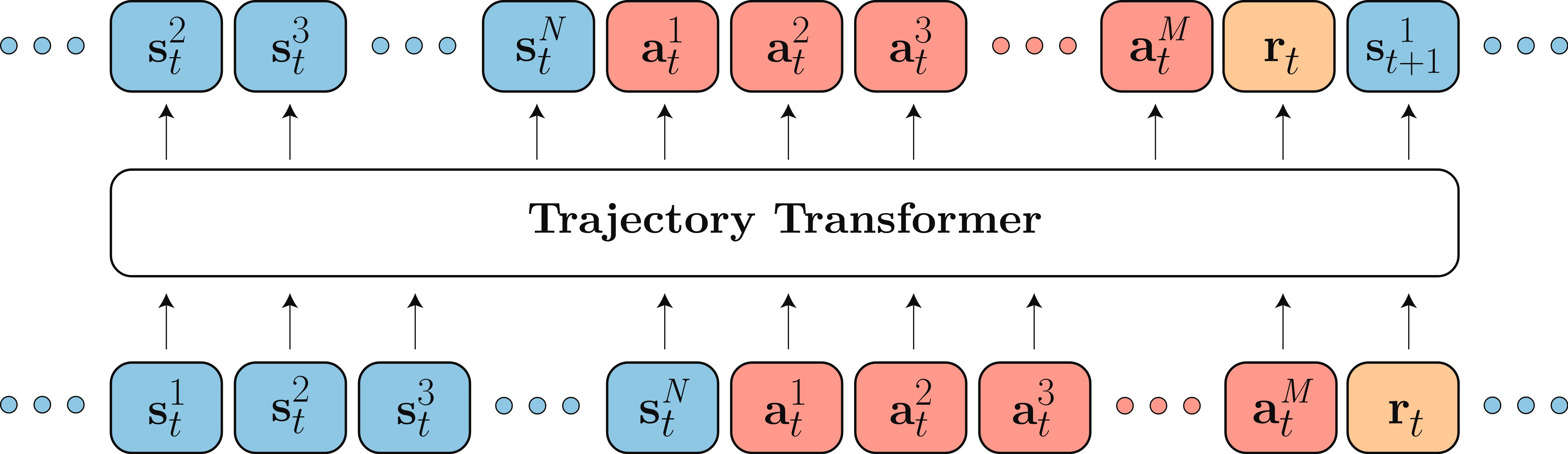
参考项目:JannerM/trajectory-transformer,详情参见:Xuan-Van/trajectory-transformer。
azure
在 Azure 上运行和管理实验的脚本集合。
file
10_nvidia.json
用于在 Linux 系统上配置 NVIDIA GPU 的驱动程序和相关设置,指定 NVIDIA 驱动程序的加载顺序和参数。
Xdummy
用于在没有物理显示器的情况下运行图形应用程序,通过模拟一个虚拟的显示器来支持图形应用程序的运行。
config.py
作用:配置 Azure 环境的参数和设置,包括 Docker 用户名、默认的 Azure GPU 型号、实例类型、区域、资源组、VM 名称和密码等。
功能:从环境变量中获取配置信息,并提供默认值。
| 类名/函数名 | 用途 |
|---|---|
get_docker_username |
获取Docker用户名,通过执行docker info命令并解析输出结果。 |
download.sh
作用:下载并解压 Azure 存储工具 azcopy。
功能:创建下载目录,下载 azcopy 的压缩包,解压并移动到指定目录,最后删除不必要的文件。
launch_plan.py
作用:启动计划任务,用于在 Azure 上执行规划脚本。
功能:定义远程函数 remote_fn,使用 doodad 库启动多个计划任务,并保存配置。
| 类名/函数名 | 用途 |
|---|---|
remote_fn |
定义在远程机器上执行的函数,用于运行计划脚本并保存配置。 |
launch_train.py
作用:启动训练任务,用于在 Azure 上执行训练脚本。
功能:定义远程函数 remote_fn,使用 doodad 库启动多个训练任务,并保存配置。
| 类名/函数名 | 用途 |
|---|---|
remote_fn |
定义在远程机器上执行的函数,用于运行训练脚本并保存配置。 |
make_fuse_config.sh
作用:生成用于挂载 Azure Blob 存储的配置文件。
功能:从环境变量中提取存储账户名称和密钥,并生成 fuse.cfg 配置文件。
mount.sh
作用:挂载 Azure Blob 存储到本地目录。
功能:创建挂载点目录,并使用 blobfuse 挂载 Azure Blob 存储。
sync.sh
作用:同步 Azure Blob 存储中的日志文件到本地目录。
功能:检查是否已登录 Azure,如果未登录则进行登录,然后使用 azcopy 同步日志文件。
config
offline.py
用于定义离线强化学习实验的超参数和设置。文件中包含多个配置块,分别用于不同的环境和任务。
基础配置 (
base):- 定义了训练和规划任务的通用超参数,如学习率、批量大小、折扣因子、模型层数、头数等。
- 使用
watch函数自动生成实验名称,根据不同的参数组合生成唯一的实验目录。
特定环境配置:
- 针对不同的环境(如
halfcheetah_medium_v2、hopper_medium_expert_v2等),定义了特定的超参数设置。 - 根据环境的特点,调整规划的视野(
horizon)、波束宽度(beam_width)等参数,以优化性能。
- 针对不同的环境(如
plotting
一个用于分析和可视化离线强化学习实验结果的工具集。
bar.png
作用:展示离线强化学习实验的平均归一化回报。
功能:通过柱状图展示不同算法在多个环境中的平均性能。
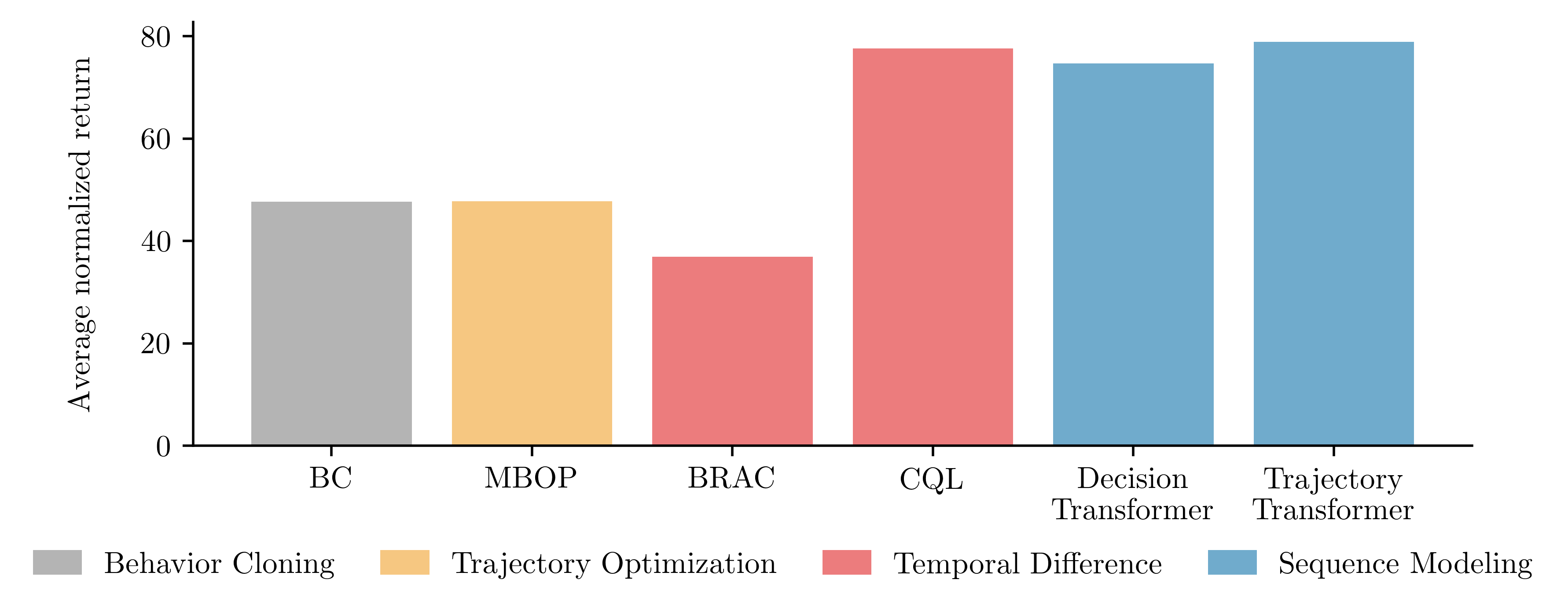
plot.py
作用:生成并保存柱状图,展示不同算法的平均归一化回报。
功能:从 scores.py 中读取数据,使用 Matplotlib 绘制柱状图,并保存为 PNG 文件。
| 类名/函数名 | 用途 |
|---|---|
watch |
一个函数,用于自动创建实验名称,根据提供的参数列表生成带有参数标签的文件夹名称。 |
read_results.py
作用:读取实验结果并计算平均值和标准误差。
功能:遍历指定目录中的实验结果文件,加载并计算每个实验的得分,输出平均值和标准误差。
| 类名/函数名 | 用途 |
|---|---|
load_results |
从给定的路径列表中加载实验结果,并计算平均分和误差。 |
load_result |
从单个实验目录中加载结果,期望目录中存在 rollout.json 文件。 |
Parser |
一个解析命令行参数的类,继承自 utils.Parser。 |
scores.py
作用:存储不同算法在不同环境中的平均得分和误差。
功能:提供一个字典,包含多个算法在多个环境中的得分和误差数据。
table.py
作用:生成 LaTeX 表格,展示不同算法在不同环境中的平均得分和误差。
功能:从 scores.py 中读取数据,生成 LaTeX 表格代码,并输出到控制台。
| 类名/函数名 | 用途 |
|---|---|
get_result |
获取特定算法、缓冲区和环境的分数和误差。 |
format_result |
格式化单个结果为LaTeX格式的字符串。 |
format_row |
格式化一行结果,包含环境和对应算法的分数。 |
format_buffer_block |
格式化一个缓冲区块,包含所有环境的结果。 |
format_algorithm |
将算法名称转换为LaTeX格式的字符串。 |
format_algorithms |
格式化所有算法名称,用于表格的头部。 |
format_averages |
格式化平均分数,用于表格底部。 |
format_averages_block |
格式化所有算法的平均分数块。 |
format_table |
格式化整个表格的LaTeX代码。 |
scripts
plan.py
作用:执行规划任务,使用预训练的 Transformer 模型生成动作序列,并在环境中执行这些动作。
功能:加载预训练模型和数据集,进行波束搜索以生成动作序列,执行动作并记录结果,最后保存规划和执行的轨迹。
| 类名/函数名 | 用途 |
|---|---|
Parser |
一个解析命令行参数的类,继承自 utils.Parser。 |
train.py
作用:训练 Transformer 模型,用于离线强化学习(Offline Reinforcement Learning, RL)任务。
功能:加载数据集,配置和初始化 Transformer 模型,设置训练器,进行模型训练,并在训练过程中保存模型状态。
| 类名/函数名 | 用途 |
|---|---|
Parser |
一个解析命令行参数的类,继承自 utils.Parser。 |
trajectory
datasets
用于处理和加载 D4RL 数据集中的序列数据。
__ init__.py
作用:初始化模块并导入相关函数和类。
功能:导入 d4rl.py 中的 load_environment 函数、sequence.py 中的所有内容以及 preprocessing.py 中的 get_preprocess_fn 函数。
| 类名/函数名 | 用途 |
|---|---|
load_environment |
从 d4rl 模块导入,用于加载环境。 |
get_preprocess_fn |
从 preprocessing 模块导入,用于获取预处理函数。 |
| ·*· | 来自 sequence.py 的所有内容 |
d4rl.py
作用:处理与 D4RL 数据集相关的操作,包括加载环境和处理数据集。
功能:提供上下文管理器 suppress_output 用于抑制输出,定义了加载环境、处理数据集和生成 Q-learning 数据集的函数。
| 类名/函数名 | 用途 |
|---|---|
suppress_output |
一个上下文管理器,用于抑制输出,将stdout和stderr重定向到空设备。 |
qlearning_dataset_with_timeouts |
构建一个用于Q学习的dataset,包含timeouts信息。 |
load_environment |
加载一个环境,抑制在加载过程中产生的输出。 |
preprocessing.py
作用:定义数据预处理函数,用于处理不同环境的观测数据。
功能:提供针对特定环境的预处理函数,如 kitchen_preprocess_fn 和 ant_preprocess_fn,并定义了 vmap 函数用于向量化处理。
| 类名/函数名 | 用途 |
|---|---|
kitchen_preprocess_fn |
对厨房环境的观测数据进行预处理,保留前30维数据。 |
ant_preprocess_fn |
对蚂蚁环境的观测数据进行预处理,保留位置和速度信息。 |
vmap |
将一个函数转换为可以处理向量输入的函数。 |
preprocess_dataset |
对整个数据集应用预处理函数。 |
get_preprocess_fn |
根据环境名称获取对应的预处理函数。 |
sequence.py
作用:定义序列数据集类,用于处理和加载序列数据。
功能:提供 SequenceDataset 和 DiscretizedDataset 类,用于加载和处理序列数据,包括分段、离散化和生成训练样本。
| 类名/函数名 | 用途 |
|---|---|
segment |
将观测数据根据终止信号分割成轨迹。 |
SequenceDataset |
一个PyTorch数据集类,用于处理序列数据。 |
SequenceDataset.__len__ |
返回数据集中的索引数量。 |
DiscretizedDataset |
继承自SequenceDataset的类,用于处理离散化的数据集。 |
DiscretizedDataset.__getitem__ |
获取数据集中的一个项目,并进行离散化处理。 |
GoalDataset |
继承自DiscretizedDataset的类,用于处理带有目标的数据集。 |
GoalDataset.__getitem__ |
获取数据集中的一个项目,并返回与目标相关的数据。 |
models
Transformer 模型的核心组件,可以方便地构建和训练 Transformer 模型,用于序列生成和条件生成任务。
ein.py
作用:定义了一个自定义的线性层 EinLinear,用于在多个模型之间共享权重。
功能:通过 torch.einsum 实现高效的矩阵乘法,支持多个模型的并行计算。
| 类名/函数名 | 用途 |
|---|---|
EinLinear |
一个自定义的线性层类,用于处理多个模型的线性变换。 |
EinLinear.__init__ |
初始化EinLinear类实例,设置模型数量、输入特征数、输出特征数和偏置。 |
EinLinear.reset_parameters |
重置EinLinear类实例的权重和偏置参数。 |
EinLinear.forward |
定义前向传播过程,使用爱因斯坦求和约定进行矩阵乘法。 |
EinLinear.extra_repr |
提供类的额外字符串表示,用于打印类的配置信息。 |
embeddings.py
作用:定义了一个平滑嵌入层 SmoothEmbedding,用于处理离散化数据的嵌入。
功能:通过加权平均的方式生成嵌入向量,支持平滑嵌入和停止标记。
| 类名/函数名 | 用途 |
|---|---|
make_weights |
创建一个权重矩阵,用于平滑嵌入。 |
add_stop_token |
向权重矩阵中添加一个停止标记。 |
SmoothEmbedding |
一个自定义的PyTorch模块,用于创建平滑嵌入。 |
SmoothEmbedding.__init__ |
初始化SmoothEmbedding模块,设置嵌入数量、嵌入维度和权重。 |
SmoothEmbedding.forward |
定义SmoothEmbedding模块的前向传播过程。 |
mlp.py
作用:定义了一个多层感知机(MLP)类 MLP,用于构建前馈神经网络。
功能:支持自定义的激活函数和输出激活函数,以及模型的参数统计和打印。
| 类名/函数名 | 用途 |
|---|---|
get_activation |
根据参数获取激活函数。 |
flatten |
将条件字典展平成一个张量。 |
MLP |
一个多层感知机(MLP)类,用于构建神经网络。 |
MLP.__init__ |
初始化MLP类,设置输入维度、隐藏层维度、输出维度、激活函数等。 |
MLP.forward |
定义MLP的前向传播过程。 |
MLP.num_parameters |
获取MLP模型的参数数量。 |
MLP.__repr__ |
提供MLP类的字符串表示,显示模型名称和参数数量。 |
FlattenMLP |
一个继承自MLP的类,用于在前向传播前展平输入。 |
FlattenMLP.forward |
定义FlattenMLP的前向传播过程,包括展平输入。 |
transformers.py
作用:定义了 Transformer 模型相关的类,包括 CausalSelfAttention、Block、GPT 和 ConditionalGPT。
功能:实现自回归 Transformer 模型,支持因果自注意力机制、位置编码、多头注意力、前馈网络等组件,并支持条件生成。
| 类名/函数名 | 用途 |
|---|---|
CausalSelfAttention |
一个自定义的因果自注意力模块类。 |
CausalSelfAttention.forward |
定义因果自注意力模块的前向传播过程。 |
Block |
一个自定义的模块类,包含因果自注意力和多层感知机。 |
Block.forward |
定义Block模块的前向传播过程。 |
GPT |
一个自定义的GPT模型类。 |
GPT._init_weights |
初始化GPT模型的权重。 |
GPT.configure_optimizers |
配置GPT模型的优化器。 |
GPT.offset_tokens |
偏移token索引。 |
GPT.pad_to_full_observation |
将序列填充到完整的观测长度。 |
GPT.verify |
验证填充操作的正确性。 |
GPT.forward |
定义GPT模型的前向传播过程。 |
ConditionalGPT |
一个自定义的条件GPT模型类。 |
ConditionalGPT.forward |
定义条件GPT模型的前向传播过程。 |
search
搜索和采样模块,用于在 Transformer 模型中进行波束搜索和规划。
__ init__.py
作用:初始化搜索模块并导入相关函数和类。
功能:导入 core.py 和 utils.py 中的所有内容。
| 类名/函数名 | 用途 |
|---|---|
* |
来自 core.py 的所有内容 |
* |
来自 utils.py 的所有内容 |
core.py
作用:定义了波束搜索和波束规划的核心函数。
功能:提供 beam_plan 和 beam_search 函数,用于在 Transformer 模型中进行波束搜索和规划。
| 类名/函数名 | 用途 |
|---|---|
beam_plan |
执行束搜索(beam search)以规划模型的行为。 |
beam_search |
执行束搜索(beam search)以找到最优序列。 |
sampling.py
作用:定义了采样相关的函数,用于从 Transformer 模型的输出中采样。
功能:提供 top_k_logits、filter_cdf、round_to_multiple、sort_2d、forward、get_logp 和 sample 函数,用于处理和采样 Transformer 模型的输出。
| 类名/函数名 | 用途 |
|---|---|
top_k_logits |
将除了前k个最高logits之外的其他值设置为负无穷,用于top-k采样。 |
filter_cdf |
根据累积分布函数(CDF)阈值过滤logits。 |
round_to_multiple |
将数字向上舍入到最近的N的倍数。 |
sort_2d |
对二维数组进行排序。 |
forward |
包装模型的前向传播,如果序列太长则进行裁剪。 |
get_logp |
获取模型输出的对数概率。 |
sample |
从模型参数化的分布中采样。 |
sample_n |
从模型中采样N个步骤的序列。 |
utils.py
作用:定义了一些辅助函数,用于处理和更新上下文。
功能:提供 make_prefix、extract_actions 和 update_context 函数,用于生成前缀、提取动作和更新上下文。
| 类名/函数名 | 用途 |
|---|---|
make_prefix |
创建前缀,用于在序列预测中包含上下文信息。 |
extract_actions |
从序列中提取动作部分。 |
update_context |
更新上下文,添加新的转换并裁剪过长的上下文。 |
utils
__ init__.py
功能: 初始化模块,导入其他模块中的类和函数。
作用: 使其他模块中的类和函数可以在当前模块中使用。
| 类名/函数名 | 用途 |
|---|---|
Parser |
解析命令行参数 |
watch |
自动生成实验名称,根据不同的参数组合生成唯一的实验目录 |
Config |
管理配置参数 |
Trainer |
管理模型的训练过程 |
make_renderer |
用于可视化环境和数据 |
Progress |
显示进度条和日志信息 |
Silent |
用于不显示进度条和日志信息 |
* |
来自arrays.py的所有内容 |
* |
来自serialization.py的所有内容 |
arrays.py
功能: 提供数组和张量的处理工具函数。
作用: 进行数据类型转换、设备管理、归一化等操作。
| 类名/函数名 | 用途 |
|---|---|
to_np |
将PyTorch张量转换为NumPy数组 |
to_torch |
将数据转换为PyTorch张量,并指定数据类型和设备 |
to_device |
将多个张量移动到指定的设备上 |
normalize |
将输入数据归一化到[0, 1]区间内 |
to_img |
将归一化后的张量转换为图像格式的NumPy数组 |
set_device |
设置全局变量DEVICE为指定的设备,并设置PyTorch的默认张量类型 |
config.py
功能: 定义了一个配置类 Config,用于管理配置参数。
作用: 提供配置参数的初始化、保存、加载和使用功能。
| 类名/函数名 | 用途 |
|---|---|
__init__ |
初始化Config类的实例,设置类名、是否打印配置信息、保存路径和其他关键字参数 |
__repr__ |
返回Config对象的字符串表示,用于打印配置信息 |
__iter__ |
返回Config对象的迭代器,用于迭代配置项 |
__getitem__ |
通过键值获取Config对象中的配置项 |
__len__ |
返回Config对象中配置项的数量 |
__call__ |
调用Config对象,返回make方法的结果 |
__getattr__ |
获取Config对象的属性,如果属性不存在则尝试从配置项中获取 |
make |
根据类名创建类的实例,如果类名包含’GPT’或’Trainer’,则将Config对象作为唯一参数传递;否则,将配置项作为关键字参数传递 |
discretization.py
功能: 定义了一个 QuantileDiscretizer 类,用于数据的离散化处理。
作用: 将连续数据离散化为多个区间,并提供离散化和重构功能。
| 类名/函数名 | 用途 |
|---|---|
QuantileDiscretizer |
一个用于数据分位数离散化的类 |
QuantileDiscretizer.__init__ |
初始化QuantileDiscretizer类的实例,设置数据和离散化数量 |
QuantileDiscretizer.__call__ |
对输入的数据进行离散化处理,并返回索引、重构值和误差 |
QuantileDiscretizer._test |
测试QuantileDiscretizer类的离散化和重构功能 |
QuantileDiscretizer.discretize |
将连续数据离散化成指定数量的分位数 |
QuantileDiscretizer.reconstruct |
根据离散化索引重构原始数据 |
QuantileDiscretizer.expectation |
计算概率分布的期望值 |
QuantileDiscretizer.percentile |
计算概率分布的百分位数 |
QuantileDiscretizer.value_expectation |
计算价值期望,包括奖励和下一个值的期望 |
QuantileDiscretizer.value_fn |
根据给定的百分位数计算价值函数 |
largest_nonzero_index |
计算一个布尔数组中每个元素为True的最大索引 |
git_utils.py
功能: 提供与 Git 相关的实用工具函数。
作用: 获取 Git 仓库信息、保存 Git 差异文件等。
| 类名/函数名 | 用途 |
|---|---|
get_repo |
获取Git仓库对象,可以指定路径和是否搜索父目录 |
get_git_rev |
获取当前Git仓库的修订版本号(commit hash) |
git_diff |
获取当前Git仓库的diff信息 |
save_git_diff |
将Git仓库的diff信息保存到文件 |
progress.py
功能: 定义了 Progress 和 Silent 类,用于显示进度条和日志信息。
作用: 在训练或处理过程中显示进度和相关信息。
| 类名/函数名 | 用途 |
|---|---|
Progress |
这是一个进度条类,用于显示任务的进度。 |
Progress.__init__ |
初始化进度条,设置总任务数、名称、列数、最大长度等参数。 |
Progress.update |
更新进度条,增加步骤数并根据需要更新速度。 |
Progress.resume |
恢复进度条显示。 |
Progress.pause |
暂停进度条显示。 |
Progress.set_description |
设置进度条的描述信息。 |
Progress.append_description |
向进度条描述信息中添加内容。 |
Progress._clear |
清除进度条显示。 |
Progress._format_percent |
格式化进度百分比。 |
Progress._format_speed |
格式化进度速度。 |
Progress._chunk |
将列表分割成指定列数的子列表。 |
Progress._format |
格式化参数描述。 |
Progress._format_chunk |
格式化单个参数块。 |
Progress._format_param |
格式化单个参数。 |
Progress.stamp |
打印进度条的当前状态。 |
Progress.close |
关闭进度条。 |
Silent |
一个沉默类,用于创建一个不执行任何操作的对象。 |
Silent.__init__ |
初始化沉默对象。 |
Silent.__getattr__ |
返回一个空函数,使得任何属性调用都不执行任何操作。 |
rendering.py
功能: 定义了多个渲染器类,用于可视化环境和数据。
作用: 提供环境状态的可视化、视频生成等功能。
| 类名/函数名 | 用途 |
|---|---|
make_renderer |
根据参数创建渲染器实例,并返回该实例。 |
split |
将序列分割为观察值、动作、奖励和价值。 |
set_state |
设置环境的状态,包括位置和速度。 |
rollout_from_state |
从给定状态和动作序列中生成观察值序列。 |
DebugRenderer.__init__ |
初始化调试渲染器。 |
DebugRenderer.render |
返回一个空的图像数组。 |
DebugRenderer.render_plan |
占位符方法,不执行任何操作。 |
DebugRenderer.render_rollout |
占位符方法,不执行任何操作。 |
Renderer.__init__ |
初始化渲染器,加载环境并设置观察和动作维度。 |
Renderer.__call__ |
调用渲染器的渲染方法。 |
Renderer.render |
渲染给定的观察值并返回图像数据。 |
Renderer.renders |
渲染多个观察值并返回图像数组。 |
Renderer.render_plan |
渲染计划并保存为视频。 |
Renderer.render_rollout |
渲染回放并保存为视频。 |
KitchenRenderer.__init__ |
初始化厨房渲染器,加载环境并设置观察和动作维度。 |
KitchenRenderer.set_obs |
设置环境的观察值。 |
KitchenRenderer.rollout |
从给定观察值和动作中生成观察值序列。 |
KitchenRenderer.render |
渲染给定观察值并返回图像。 |
KitchenRenderer.renders |
渲染多个观察值并返回图像数组。 |
KitchenRenderer.render_plan |
渲染计划并保存为视频。 |
KitchenRenderer.render_rollout |
渲染回放并保存为视频。 |
KitchenRenderer.__call__ |
调用渲染器的渲染方法。 |
AntMazeRenderer.__init__ |
初始化AntMaze渲染器,加载环境并设置观察和动作维度。 |
AntMazeRenderer.renders |
渲染并保存路径图像。 |
AntMazeRenderer.plot_boundaries |
绘制AntMaze环境的边界。 |
AntMazeRenderer.render_plan |
渲染计划并保存为视频。 |
AntMazeRenderer.render_rollout |
渲染回放并保存为视频。 |
Maze2dRenderer._is_in_collision |
检查给定坐标是否与墙壁发生碰撞。 |
Maze2dRenderer.plot_boundaries |
绘制Maze2D环境的边界。 |
Maze2dRenderer.renders |
渲染并保存路径图像,添加偏移量。 |
serialization.py
功能: 提供模型和配置的序列化和反序列化功能。
作用: 保存和加载模型、配置文件,管理文件目录。
| 类名/函数名 | 用途 |
|---|---|
mkdir |
创建目录,如果目录已存在则返回False,否则返回True。 |
get_latest_epoch |
在给定的加载路径中查找最新的epoch编号。 |
load_model |
加载模型,支持加载指定epoch或最新的模型状态。 |
load_config |
从指定路径加载配置文件。 |
load_from_config |
根据配置文件创建模型或对象。 |
load_args |
从指定路径加载参数文件。 |
setup.py
功能: 提供实验设置和参数管理功能。
作用: 解析命令行参数、加载配置文件、设置随机种子等。
| 类名/函数名 | 用途 |
|---|---|
set_seed |
设置随机种子,确保随机操作的可重复性。 |
watch |
创建一个函数,用于生成基于参数的实验名称。 |
Parser |
一个继承自Tap的类,用于解析命令行参数并进行一些额外的操作。 |
Parser.save |
保存解析后的参数到JSON文件。 |
Parser.parse_args |
解析命令行参数,并执行一系列初始化操作。 |
Parser.read_config |
从配置文件中读取参数。 |
Parser.add_extras |
用命令行参数覆盖配置文件中的参数。 |
Parser.set_seed |
根据参数设置随机种子。 |
Parser.generate_exp_name |
生成实验名称。 |
Parser.mkdir |
创建实验所需的目录结构,并保存参数。 |
Parser.get_commit |
获取当前git commit的版本号。 |
Parser.save_diff |
保存git的差异信息到文件。 |
timer.py
功能: 定义了一个简单的计时器类 Timer。
作用: 用于测量代码段的执行时间。
| 类名/函数名 | 用途 |
|---|---|
Timer |
这是一个计时器类,用于测量代码执行时间。 |
Timer.__init__ |
初始化计时器对象,并记录开始时间。 |
Timer.__call__ |
返回自计时器创建或重置以来经过的时间,并可选择重置计时器。 |
training.py
功能: 定义了一个训练器类 Trainer,用于管理模型的训练过程。
作用: 提供训练循环、优化器管理、学习率衰减等功能。
| 类名/函数名 | 用途 |
|---|---|
to |
将一组张量移动到指定的设备(如CPU或GPU)。 |
Trainer |
一个用于训练模型的类。 |
Trainer.get_optimizer |
获取或创建模型的优化器。 |
Trainer.train |
训练模型,包括前向传播、反向传播和参数更新。 |
video.py
功能: 提供视频保存功能。
作用: 将图像序列保存为视频文件。
| 类名/函数名 | 用途 |
|---|---|
_make_dir |
检查给定文件路径的文件夹是否存在,如果不存在则创建该文件夹。 |
save_video |
保存视频帧为视频文件,支持指定文件名、帧率和视频格式。 |
save_videos |
将多个视频帧数组合并并保存为一个视频文件,支持指定文件名和其他保存参数。 |
environment.yml
定义了一个名为 trajectory 的 Conda 环境,并指定了该环境所需的所有依赖项。
pretrained.sh
一个 Bash 脚本,用于自动化下载和解压预训练模型和计划文件,并将它们存储在指定的目录中。过程如下:
- 设置下载路径为
logs目录。 - 如果
logs目录不存在,则创建该目录。 - 下载包含预训练模型的ZIP文件,并将其解压到
logs目录中,然后删除ZIP文件。 - 下载包含计划文件的TAR文件,并将其解压到
logs目录中,然后删除TAR文件和解压后的目录。
README.md
安装
所有 Python 依赖项都在 environment.yml 文件中。安装步骤如下:
1 | |
为了确保可复现性,还提供了一个 Dockerfile,但 conda 安装应该能在大多数标准的 Linux 机器上工作。
使用方法
训练一个 Transformer 模型:
1 | |
复现离线强化学习结果:
1 | |
默认情况下,这些命令将使用 config/offline.py 中的超参数。你可以使用运行时标志覆盖它们:
1 | |
预训练模型
提供了 16 个数据集的预训练模型:{halfcheetah, hopper, walker2d, ant}-{expert-v2, medium-expert-v2, medium-v2, medium-replay-v2}。使用 ./pretrained.sh 下载它们。
模型将保存在 logs/$DATASET/gpt/pretrained。使用这些模型进行规划时,使用 gpt_loadpath 标志引用它们:
1 | |
pretrained.sh 还会下载每个模型的 15 个计划,保存到 logs/$DATASET/plans/pretrained,使用 python plotting/read_results.py 读取它们。
创建表格
要创建论文中的离线 RL 结果表格,运行 python plotting/table.py,这将打印一个可以复制到 LaTeX 文档中的表格。
创建平均性能图
要创建平均性能图,运行 python plotting/plot.py。
Docker
复制 MuJoCo 密钥到 Docker 构建上下文并构建容器:
1 | |
测试容器:
1 | |
在 Azure 上运行
设置
- 在 Azure 上启动作业需要一个额外的 Python 依赖项:
1 | |
- 标记在 Docker 中构建的镜像,并将其推送到 Docker Hub:
1 | |
更新
azure/config.py,可以直接修改文件或设置相关的环境变量。要设置AZURE_STORAGE_CONNECTION变量,请导航到存储帐户的Access keys部分。点击Show keys并复制Connection string。下载 AzCopy:
./azure/download.sh
使用方法
使用 python azure/launch_train.py 启动训练作业,使用 python azure/launch_plan.py 启动规划作业。
这些脚本不接受运行时参数。相反,它们使用 params_to_sweep 中的参数的笛卡尔积来运行相应的脚本(scripts/train.py 和 scripts/plan.py)。
查看结果
要从 Azure 存储容器同步结果,请运行 ./azure/sync.sh。
要挂载存储容器:
- 使用
./azure/make_fuse_config.sh创建一个 blobfuse 配置。 - 运行
./azure/mount.sh将存储容器挂载到~/azure_mount。
要卸载容器,请运行 sudo umount -f ~/azure_mount; rm -r ~/azure_mount。
致谢
GPT实现来自 karpathy/minGPT 。
setup.py
一个用于配置 Python 包的安装脚本,定义和配置 Python 包的安装过程:
- 导入
setup函数和find_packages函数,用于配置包的安装。 - 使用
setup函数配置包的安装。name参数指定了包的名称,packages参数使用find_packages函数自动查找并包含所有包。
第三方库
| 函数名 | 用途 |
|---|---|
| contextlib.contextmanager | 装饰器,用于创建上下文管理器 |
| contextlib.redirect_stderr | 重定向stderr到指定的文件或文件类对象 |
| contextlib.redirect_stdout | 重定向stdout到指定的文件或文件类对象 |
| decode | 将字节字符串解码为普通字符串 |
| discretization | 从trajectory.utils模块导入的离散化工具 |
| F.cross_entropy | PyTorch的交叉熵损失函数 |
| F.softmax | PyTorch的softmax函数 |
| filter | 过滤可训练参数 |
| getattr | 获取对象的属性 |
| git.Repo | 创建Git仓库对象,用于操作Git仓库 |
| glob | 提供文件路径模式匹配 |
| glob.glob1 | 从指定目录中搜索匹配特定模式的文件名 |
| gym.Env.unwrapped | 获取环境的未包装版本 |
| gym.make | 创建一个指定环境的实例 |
| importlib.import_module | 动态导入模块 |
| json | 用于处理JSON数据 |
| json.dump | 将JSON数据写入文件 |
| json.load | 从文件中加载JSON数据 |
| math | 提供数学相关的函数,如平方根计算 |
| math.ceil | 返回大于或等于给定数字的最小整数 |
| math.cos | 计算余弦值,用于学习率衰减的计算 |
| math.fabs | 返回给定数字的绝对值 |
| math.floor | 返回小于或等于给定数字的最大整数 |
| math.pow | 计算给定数字的幂 |
| math.sqrt | 计算平方根 |
| matplotlib.pyplot | 用于绘制图形和可视化数据 |
| model.configure_optimizers | 配置模型的优化器(假设这是模型的一个方法) |
| mujoco_py.MjRenderContextOffscreen | 创建一个离屏渲染上下文,用于MuJoCo环境 |
| nn.Dropout | PyTorch的dropout层,用于正则化 |
| nn.Embedding | PyTorch的嵌入层 |
| nn.GELU | PyTorch的GELU激活函数 |
| nn.init._calculate_fan_in_and_fan_out | 计算权重张量的fan_in和fan_out值 |
| nn.init.kaiming_uniform_ | 使用Kaiming均匀分布初始化权重 |
| nn.init.uniform_ | 使用均匀分布初始化张量 |
| nn.LayerNorm | PyTorch的层归一化层 |
| nn.Linear | PyTorch的线性层 |
| nn.Module | PyTorch的基类,用于构建自定义的神经网络模块 |
| nn.Parameter | 将张量转换为模型的参数 |
| nn.Sequential | PyTorch的顺序容器,用于包装一系列层 |
| numpy | 用于数值计算和数组操作 |
| numpy.all | 检查数组中所有元素是否都为True |
| numpy.arange | 生成等差数列 |
| numpy.argmax | 返回沿给定轴最大值的索引 |
| numpy.concatenate | 连接数组 |
| numpy.cumsum | 计算数组的累积和 |
| numpy.expand_dims | 增加数组的维度 |
| numpy.max | 计算数组的最大值 |
| numpy.ndarray.max | 计算数组沿指定轴的最大值 |
| numpy.ndarray.min | 计算数组沿指定轴的最小值 |
| numpy.ndarray.shape | 获取数组的形状 |
| numpy.ndarray.squeeze | 移除数组中长度为1的维度 |
| numpy.prod | 计算数组元素的乘积 |
| numpy.random.randint | 生成指定范围内的随机整数 |
| numpy.random.seed | 设置NumPy随机数生成器的种子 |
| numpy.sort | 对数组进行排序 |
| numpy.take_along_axis | 沿着指定轴取数组元素 |
| numpy.transpose | 用于对数组进行轴的转置操作 |
| os | 提供操作系统相关的功能,如路径操作和环境变量设置 |
| os.devnull | 打开一个指向空设备(/dev/null)的文件,用于抑制输出 |
| os.environ.get | 从环境变量中获取值 |
| os.makedirs | 创建给定路径的目录,如果中间目录不存在也会一并创建 |
| os.path | 用于处理文件和目录路径 |
| os.path.abspath | 获取路径的绝对路径 |
| os.path.dirname | 获取路径的目录名 |
| os.path.exists | 检查给定路径是否存在 |
| os.path.join | 连接路径组件,生成完整的文件路径 |
| os.path.realpath | 获取路径的规范化绝对路径 |
| os.system | 执行系统命令 |
| p.numel | 获取张量中元素的总数 |
| pdb | Python调试器,用于调试代码 |
| pickle.dump | 将对象序列化并保存到文件 |
| pickle.load | 从文件中加载Python对象 |
| random.seed | 设置随机数生成器的种子 |
| re.sub | 替换字符串中的模式匹配项 |
| repo.active_branch.commit.name_rev | 获取当前活动分支的最新提交的修订版本号 |
| repo.git.diff | 获取Git仓库的差异信息 |
| repo.head.is_detached | 检查当前HEAD是否处于分离HEAD状态 |
| repo.head.object.name_rev | 获取HEAD的修订版本号 |
| save_doodad_config | 从 doodad.wrappers.easy_launch 模块导入,用于保存配置 |
| shlex.split | 将字符串分割成命令行参数列表 |
| skvideo.io.vwrite | 将视频帧写入视频文件 |
| subprocess.check_output | 执行命令并获取输出 |
| subprocess.Popen | 创建一个新的进程,用于执行命令 |
| sum | 计算参数数量总和 |
| sweep_function | 从 doodad.wrappers.easy_launch 模块导入,用于执行参数扫描 |
| Tap | 一个用于解析命令行参数的第三方库 |
| time.sleep | 暂停执行指定的秒数 |
| time.time | 获取当前时间的时间戳 |
| Timer | 自定义的计时器类,用于测量时间 |
| to_torch | 从trajectory.utils.arrays模块导入的函数,用于将数据转换为PyTorch张量 |
| torch | PyTorch库,用于张量操作和自动微分 |
| torch.arange | 创建一个范围的一维张量 |
| torch.cat | PyTorch的函数,用于连接张量 |
| torch.clone | PyTorch的函数,克隆一个张量 |
| torch.cpu | 将张量移动到CPU设备上 |
| torch.cuda.manual_seed_all | 设置所有GPU的随机种子 |
| torch.cumsum | 计算累积和 |
| torch.detach | 从当前计算图中分离出张量,返回一个新的张量,不会在反向传播中计算梯度 |
| torch.einsum | PyTorch的函数,根据爱因斯坦求和约定执行张量运算 |
| torch.get_logp | 从模型中获取对数概率 |
| torch.is_tensor | 检查给定对象是否为PyTorch张量 |
| torch.load | 加载PyTorch模型或张量 |
| torch.log_softmax | 计算log-softmax |
| torch.logp | 计算模型输出的对数概率 |
| torch.manual_seed | 设置PyTorch的随机种子 |
| torch.masked_fill | PyTorch的函数,用于根据掩码填充张量中的值 |
| torch.matmul | PyTorch的函数,用于矩阵乘法 |
| torch.multinomial | 从概率分布中采样 |
| torch.nn as nn | PyTorch的神经网络模块,用于构建神经网络层和函数 |
| torch.nn.functional as F | PyTorch的函数式接口,提供神经网络相关的函数 |
| torch.nn.Module.load_state_dict | 将模型的状态字典加载到模型中 |
| torch.nn.utils.clip_grad_norm_ | 裁剪梯度范数,防止梯度爆炸 |
| torch.no_grad | 装饰器,用于指定一个代码块不需要计算梯度 |
| torch.ones | PyTorch的函数,创建一个填充有一的张量 |
| torch.sample_n | 从模型中采样n个动作 |
| torch.set_default_tensor_type | 设置默认的张量类型 |
| torch.set_grad_enabled | 用于设置梯度计算的启用状态 |
| torch.softmax | 计算softmax |
| torch.sort | 对张量进行排序 |
| torch.tensor | 创建一个PyTorch张量 |
| torch .to | 将模型或张量移动到指定的设备(如CPU或GPU) |
| torch.topk | 返回张量中值最大的k个元素 |
| torch.transpose | PyTorch的函数,用于转置张量 |
| torch.tril | PyTorch的函数,返回一个矩阵的下三角部分 |
| torch.unsqueeze | 增加张量的维度 |
| torch.utils.data.DataLoader | PyTorch数据加载器,用于批量加载数据 |
| torch.utils.data.Dataset | PyTorch数据集基类 |
| torch.zeros | PyTorch的函数,创建一个填充有零的张量 |