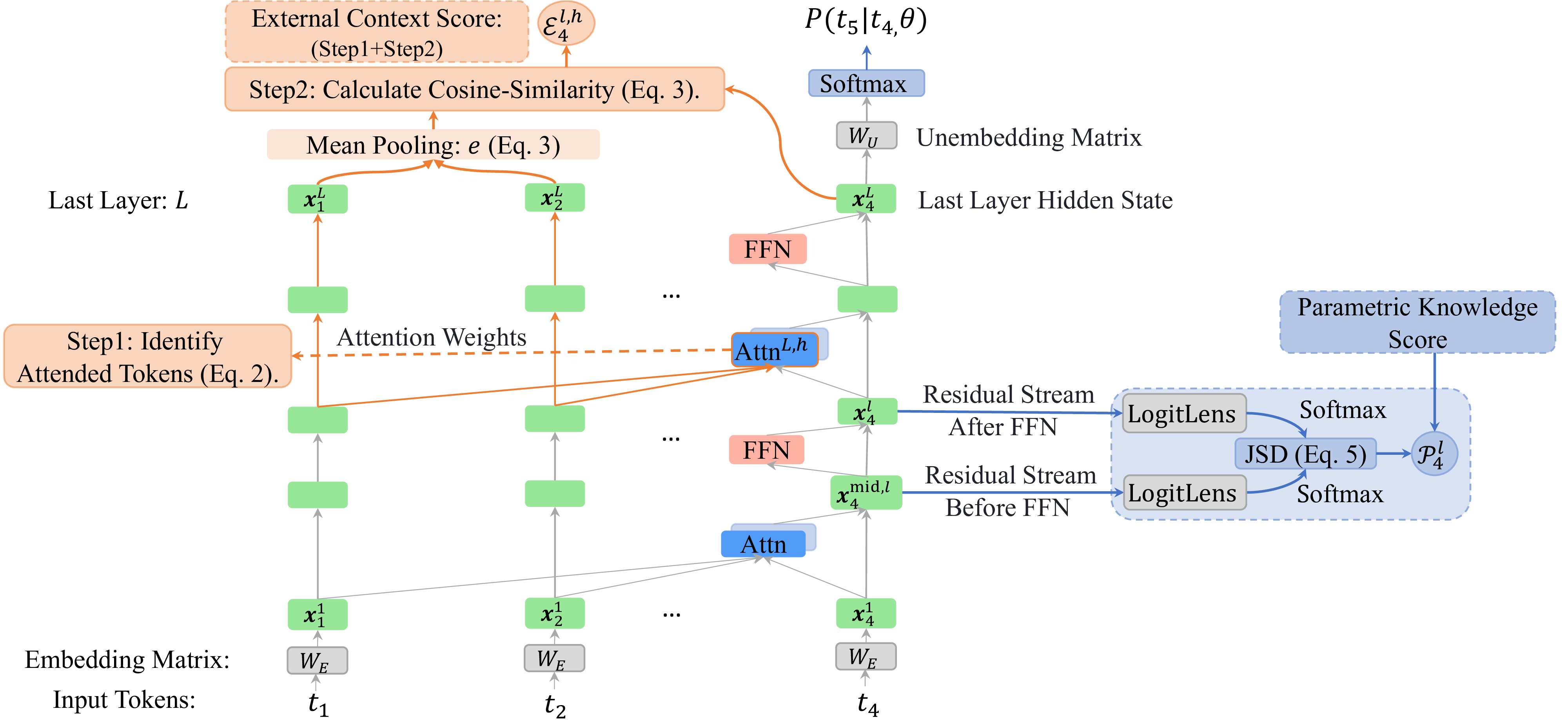
import torch import json import argparse from transformers import AutoModelForCausalLM, AutoTokenizer from torch.nn import functional as F from tqdm import tqdm
加载 response:
1 2 3 4 5 6 7
response = [] withopen("../dataset/response.jsonl", 'r') as f: for line in f: data = json.loads(line) response.append(data)
[
{
"id": "27",
"source_id": "15596",
"model": "llama-2-7b-chat",
"temperature": 0.7,
"labels": [],
"split": "test",
"quality": "good",
"response": "FBI charges Philadelphia woman with attempting to join ISIS after purchasing electronic visa for Turkey. Keonna Thomas, 30, also known as \"Young Lioness\" and \"Fatayat Al Khilafah,\" made numerous social media posts expressing desire to fight for ISIS. She could face 15 years in prison. Three women have been arrested this week on terror charges, including two in New York who were accused of planning to build an explosive device for attacks in the US."
}
]
加载 source_info:
1 2 3 4 5 6 7
source_info_dict = {} withopen("../dataset/source_info.jsonl", 'r') as f: for line in f: data = json.loads(line) source_info_dict[data['source_id']] = data
{
"15596": {
"source_id": "15596",
"task_type": "Summary",
"source": "CNN/DM",
"source_info": "The FBI charged a Philadelphia woman on Thursday with trying to travel overseas to fight for ISIS. She's one of three women arrested this week on terror charges. Two New York women were also taken into custody. An FBI complaint cites numerous social media messages dating back to August 2013 that were sent by Keonna Thomas, 30, also known as \"Young Lioness\" and \"Fatayat Al Khilafah.\" One Twitter message said, \"If we truly knew the realities ... we all would be rushing to join our brothers in the front lines pray ALLAH accept us as shuhada [martyrs].\" Another said, \"When you're a mujahid [violent jihadi fighter] your death becomes a wedding.\" The FBI said Thomas purchased an electronic visa to Turkey on March 23. Turkey is known as the easiest place from which to enter Syria and join ISIS. An ISIS manual advises recruits to buy round-trip tickets to vacation spots such as Spain and then purchase tickets for their real destination once they arrive overseas, the FBI said. On March 26, Thomas purchased a ticket to Barcelona, with a March 29 departure and an April 15 return to the United States, the complaint said. It's not clear when or where she was arrested. She was charged with knowingly attempting to provide material support and resources to a designated foreign terrorist organization. She could be sentenced to 15 years in prison. On Thursday, Noelle Velentzas, 28, and her former roommate, Asia Siddiqui, 31, were arrested in New York and accused of planning to build an explosive device for attacks in the United States, federal prosecutors said. In the past 18 months, the Justice Department's National Security Division has prosecuted or is prosecuting more than 30 cases of people attempting to travel abroad to join or provide support to terrorist groups. Of those cases, 18 allegedly involve support to ISIS. \"The terrorist threat is more decentralized, more diffuse, more complicated,\" Homeland Security Secretary Jeh Johnson told reporters Thursday. \"It involves the potential lone wolf actor, it involves the effective use of social media, the Internet.\"\n",
"prompt": "Summarize the following news within 86 words:\nThe FBI charged a Philadelphia woman on Thursday with trying to travel overseas to fight for ISIS. She's one of three women arrested this week on terror charges. Two New York women were also taken into custody. An FBI complaint cites numerous social media messages dating back to August 2013 that were sent by Keonna Thomas, 30, also known as \"Young Lioness\" and \"Fatayat Al Khilafah.\" One Twitter message said, \"If we truly knew the realities ... we all would be rushing to join our brothers in the front lines pray ALLAH accept us as shuhada [martyrs].\" Another said, \"When you're a mujahid [violent jihadi fighter] your death becomes a wedding.\" The FBI said Thomas purchased an electronic visa to Turkey on March 23. Turkey is known as the easiest place from which to enter Syria and join ISIS. An ISIS manual advises recruits to buy round-trip tickets to vacation spots such as Spain and then purchase tickets for their real destination once they arrive overseas, the FBI said. On March 26, Thomas purchased a ticket to Barcelona, with a March 29 departure and an April 15 return to the United States, the complaint said. It's not clear when or where she was arrested. She was charged with knowingly attempting to provide material support and resources to a designated foreign terrorist organization. She could be sentenced to 15 years in prison. On Thursday, Noelle Velentzas, 28, and her former roommate, Asia Siddiqui, 31, were arrested in New York and accused of planning to build an explosive device for attacks in the United States, federal prosecutors said. In the past 18 months, the Justice Department's National Security Division has prosecuted or is prosecuting more than 30 cases of people attempting to travel abroad to join or provide support to terrorist groups. Of those cases, 18 allegedly involve support to ISIS. \"The terrorist threat is more decentralized, more diffuse, more complicated,\" Homeland Security Secretary Jeh Johnson told reporters Thursday. \"It involves the potential lone wolf actor, it involves the effective use of social media, the Internet.\"\n\noutput:"
}
}
FBI charges Philadelphia woman with attempting to join ISIS after purchasing electronic visa for Turkey. Keonna Thomas, 30, also known as "Young Lioness" and "Fatayat Al Khilafah," made numerous social media posts expressing desire to fight for ISIS. She could face 15 years in prison. Three women have been arrested this week on terror charges, including two in New York who were accused of planning to build an explosive device for attacks in the US.
15596
0.7
Summarize the following news within 86 words:
The FBI charged a Philadelphia woman on Thursday with trying to travel overseas to fight for ISIS. She's one of three women arrested this week on terror charges. Two New York women were also taken into custody. An FBI complaint cites numerous social media messages dating back to August 2013 that were sent by Keonna Thomas, 30, also known as "Young Lioness" and "Fatayat Al Khilafah." One Twitter message said, "If we truly knew the realities ... we all would be rushing to join our brothers in the front lines pray ALLAH accept us as shuhada [martyrs]." Another said, "When you're a mujahid [violent jihadi fighter] your death becomes a wedding." The FBI said Thomas purchased an electronic visa to Turkey on March 23. Turkey is known as the easiest place from which to enter Syria and join ISIS. An ISIS manual advises recruits to buy round-trip tickets to vacation spots such as Spain and then purchase tickets for their real destination once they arrive overseas, the FBI said. On March 26, Thomas purchased a ticket to Barcelona, with a March 29 departure and an April 15 return to the United States, the complaint said. It's not clear when or where she was arrested. She was charged with knowingly attempting to provide material support and resources to a designated foreign terrorist organization. She could be sentenced to 15 years in prison. On Thursday, Noelle Velentzas, 28, and her former roommate, Asia Siddiqui, 31, were arrested in New York and accused of planning to build an explosive device for attacks in the United States, federal prosecutors said. In the past 18 months, the Justice Department's National Security Division has prosecuted or is prosecuting more than 30 cases of people attempting to travel abroad to join or provide support to terrorist groups. Of those cases, 18 allegedly involve support to ISIS. "The terrorist threat is more decentralized, more diffuse, more complicated," Homeland Security Secretary Jeh Johnson told reporters Thursday. "It involves the potential lone wolf actor, it involves the effective use of social media, the Internet."
output:
[{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user',
'content': 'Summarize the following news within 86 words:\nThe FBI charged a Philadelphia woman on Thursday with trying to travel overseas to fight for ISIS. She\'s one of three women arrested this week on terror charges. Two New York women were also taken into custody. An FBI complaint cites numerous social media messages dating back to August 2013 that were sent by Keonna Thomas, 30, also known as "Young Lioness" and "Fatayat Al Khilafah." One Twitter message said, "If we truly knew the realities ... we all would be rushing to join our brothers in the front lines pray ALLAH accept us as shuhada [martyrs]." Another said, "When you\'re a mujahid [violent jihadi fighter] your death becomes a wedding." The FBI said Thomas purchased an electronic visa to Turkey on March 23. Turkey is known as the easiest place from which to enter Syria and join ISIS. An ISIS manual advises recruits to buy round-trip tickets to vacation spots such as Spain and then purchase tickets for their real destination once they arrive overseas, the FBI said. On March 26, Thomas purchased a ticket to Barcelona, with a March 29 departure and an April 15 return to the United States, the complaint said. It\'s not clear when or where she was arrested. She was charged with knowingly attempting to provide material support and resources to a designated foreign terrorist organization. She could be sentenced to 15 years in prison. On Thursday, Noelle Velentzas, 28, and her former roommate, Asia Siddiqui, 31, were arrested in New York and accused of planning to build an explosive device for attacks in the United States, federal prosecutors said. In the past 18 months, the Justice Department\'s National Security Division has prosecuted or is prosecuting more than 30 cases of people attempting to travel abroad to join or provide support to terrorist groups. Of those cases, 18 allegedly involve support to ISIS. "The terrorist threat is more decentralized, more diffuse, more complicated," Homeland Security Secretary Jeh Johnson told reporters Thursday. "It involves the potential lone wolf actor, it involves the effective use of social media, the Internet."\n\noutput:'}]
将 messages 转换为结构化文本字符串:
1 2
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True) # 不进行分词,同时添加一个生成提示的标记 print(text)
<s>[INST] <<SYS>>
You are a helpful assistant.
<</SYS>>
Summarize the following news within 86 words:
The FBI charged a Philadelphia woman on Thursday with trying to travel overseas to fight for ISIS. She's one of three women arrested this week on terror charges. Two New York women were also taken into custody. An FBI complaint cites numerous social media messages dating back to August 2013 that were sent by Keonna Thomas, 30, also known as "Young Lioness" and "Fatayat Al Khilafah." One Twitter message said, "If we truly knew the realities ... we all would be rushing to join our brothers in the front lines pray ALLAH accept us as shuhada [martyrs]." Another said, "When you're a mujahid [violent jihadi fighter] your death becomes a wedding." The FBI said Thomas purchased an electronic visa to Turkey on March 23. Turkey is known as the easiest place from which to enter Syria and join ISIS. An ISIS manual advises recruits to buy round-trip tickets to vacation spots such as Spain and then purchase tickets for their real destination once they arrive overseas, the FBI said. On March 26, Thomas purchased a ticket to Barcelona, with a March 29 departure and an April 15 return to the United States, the complaint said. It's not clear when or where she was arrested. She was charged with knowingly attempting to provide material support and resources to a designated foreign terrorist organization. She could be sentenced to 15 years in prison. On Thursday, Noelle Velentzas, 28, and her former roommate, Asia Siddiqui, 31, were arrested in New York and accused of planning to build an explosive device for attacks in the United States, federal prosecutors said. In the past 18 months, the Justice Department's National Security Division has prosecuted or is prosecuting more than 30 cases of people attempting to travel abroad to join or provide support to terrorist groups. Of those cases, 18 allegedly involve support to ISIS. "The terrorist threat is more decentralized, more diffuse, more complicated," Homeland Security Secretary Jeh Johnson told reporters Thursday. "It involves the potential lone wolf actor, it involves the effective use of social media, the Internet."
output: [/INST]
构建模型完整的输入输出:
1 2
input_text = text + response_rag print(input_text)
<s>[INST] <<SYS>>
You are a helpful assistant.
<</SYS>>
Summarize the following news within 86 words:
The FBI charged a Philadelphia woman on Thursday with trying to travel overseas to fight for ISIS. She's one of three women arrested this week on terror charges. Two New York women were also taken into custody. An FBI complaint cites numerous social media messages dating back to August 2013 that were sent by Keonna Thomas, 30, also known as "Young Lioness" and "Fatayat Al Khilafah." One Twitter message said, "If we truly knew the realities ... we all would be rushing to join our brothers in the front lines pray ALLAH accept us as shuhada [martyrs]." Another said, "When you're a mujahid [violent jihadi fighter] your death becomes a wedding." The FBI said Thomas purchased an electronic visa to Turkey on March 23. Turkey is known as the easiest place from which to enter Syria and join ISIS. An ISIS manual advises recruits to buy round-trip tickets to vacation spots such as Spain and then purchase tickets for their real destination once they arrive overseas, the FBI said. On March 26, Thomas purchased a ticket to Barcelona, with a March 29 departure and an April 15 return to the United States, the complaint said. It's not clear when or where she was arrested. She was charged with knowingly attempting to provide material support and resources to a designated foreign terrorist organization. She could be sentenced to 15 years in prison. On Thursday, Noelle Velentzas, 28, and her former roommate, Asia Siddiqui, 31, were arrested in New York and accused of planning to build an explosive device for attacks in the United States, federal prosecutors said. In the past 18 months, the Justice Department's National Security Division has prosecuted or is prosecuting more than 30 cases of people attempting to travel abroad to join or provide support to terrorist groups. Of those cases, 18 allegedly involve support to ISIS. "The terrorist threat is more decentralized, more diffuse, more complicated," Homeland Security Secretary Jeh Johnson told reporters Thursday. "It involves the potential lone wolf actor, it involves the effective use of social media, the Internet."
output: [/INST]FBI charges Philadelphia woman with attempting to join ISIS after purchasing electronic visa for Turkey. Keonna Thomas, 30, also known as "Young Lioness" and "Fatayat Al Khilafah," made numerous social media posts expressing desire to fight for ISIS. She could face 15 years in prison. Three women have been arrested this week on terror charges, including two in New York who were accused of planning to build an explosive device for attacks in the US.
将文本字符串转换为 token ID 序列,text 为模型输入的文本(系统提示+问题),response_rag 为模型的回应:
# 判断给定的 token 是否属于预定义的幻觉文本片段 defis_hallucination_token(token_id, hallucination_spans): for span in hallucination_spans: if token_id >= span[0] and token_id <= span[1]: returnTrue returnFalse
if is_hallucination_token(seq_i, hallucination_spans): # 确认当前 token ID 是否属于幻觉文本片段 hallucination_label.append(1) else: hallucination_label.append(0)
external_similarity.append(cosine_similarity.cpu().tolist()) parameter_knowledge_difference.append([calculate_dist(value[0][0, seq_i, :], value[1][0, seq_i, :]) for value in logits_dict.values()]) torch.cuda.empty_cache()
withopen("../output/llama2_7B_response_token.json", "w") as f: json.dump(select_response, f, ensure_ascii=False)
2.2.2 chunk 级别
导入必要的包:
1 2 3 4 5 6 7 8 9 10
import sys sys.path.insert(0, '../transformers/src') import torch import json import numpy as np import argparse from transformers import AutoModelForCausalLM, AutoTokenizer from torch.nn import functional as F from tqdm import tqdm from sentence_transformers import SentenceTransformer
[
{
"id": "45",
"source_id": "15599",
"model": "llama-2-7b-chat",
"temperature": 0.7,
"labels": [],
"split": "test",
"quality": "good",
"response": "Blue Bell ice cream has temporarily shut down one of its manufacturing plants after discovering listeria contamination in a serving of ice cream produced at the plant. The Centers for Disease Control and Prevention (CDC) has warned consumers not to eat any Blue Bell-branded products made at the Broken Arrow, Oklahoma plant, including 3-ounce servings of ice cream marked with certain codes. This is the third time Blue Bell has taken action due to a listeria outbreak at a Kansas hospital that served the company's ice cream. Investigations into the possible connection between the ice cream and the infections are ongoing. The company has recalled other products and advises individuals and institutions to check their freezers for the recalled items and throw them away. This is the first product recall in Blue Bell's 108-year history.",
"response_spans": [
[
0,
506
],
[
491,
840
]
]
}
]
加载 source_info:
1 2 3 4 5 6 7
source_info_dict = {} withopen("../dataset/source_info_spans.jsonl", 'r') as f: for line in f: data = json.loads(line) source_info_dict[data['source_id']] = data
{
"15599": {
"source_id": "15599",
"task_type": "Summary",
"source": "CNN/DM",
"source_info": "Blue Bell ice cream has temporarily shut down one of its manufacturing plants over the discovery of listeria contamination in a serving of ice cream originating from that plant. Public health officials warned consumers Friday not to eat any Blue Bell-branded products made at the company's Broken Arrow, Oklahoma, plant. That includes 3-ounce servings of Blue Bell ice cream from this plant that went to institutions in containers marked with the letters O, P, Q, R, S or T behind the coding date. The warning by the Centers for Disease Control and Prevention does not affect other Blue Bell ice cream, including other 3-ounce servings, not made at the plant. But Blue Bell has recalled other products. The company is shutting down the Broken Arrow facility \"out of an abundance of caution\" to search for a possible cause of contamination. It is the third time Blue Bell has taken action in light of a listeria outbreak at a Kansas hospital that served the company's ice cream. Listeria monocytogenes was recently found in a cup of ice cream recovered from the hospital. The cup contaminated with the bacteria was produced at the Broken Arrow plant in April 2014, Blue Bell said. And, according to the CDC, listeria bacteria was found in additional samples of the same product that were recovered from the plant. The bacteria in the hospital sample and the factory sample appeared to match each other genetically, the CDC said. But they did not appear identical to listeria samples taken from patients infected in the Kansas outbreak. In a separate outbreak in Texas, the CDC did find that listeria samples taken from patients who came down with listeriosis between 2010 and 2014 in a hospital that served 3-ounce Blue Bell cups matched the listeria in recovered samples. None of this means the ice cream is the source of either spate of the infections. \"Investigation to determine whether these illnesses are related to exposure to Blue Bell products is ongoing,\" the CDC said. In early March, in light of the Kansas listeria outbreak, Blue Bell recalled a group of products made at a plant in Texas. It later added 3-ounce cup servings to the recall. Five people were infected and three died in the past year in Kansas from listeria that might be linked to Blue Bell Creameries products, according to the CDC. All five of them were hospitalized at the same hospital before developing listeriosis, the CDC said. At least four of them had consumed milkshakes made with Blue Bell ice cream before developing the infection. \"We are devastated and know that Blue Bell has to be and can be better than this,\" Paul Kruse, Blue Bell CEO and president, said in a statement. \"Quality and safety have always been our top priorities. We are deeply saddened and concerned for all those who have been affected.\" The CDC advises that individuals and institutions should check their freezers for the recalled products and throw them away. In a statement on its website, Blue Bell said \"this recall in no way includes Blue Bell ice cream half gallons, pints, quarts, 3 gallons or other 3 oz. cups.\" This has been the first product recall in the 108-year history of Blue Bell Creameries, the company said. Listeriosis is a serious infection caused by eating food contaminated with listeria, and primarily affects the elderly, pregnant women, newborns and people with weakened immune systems, according to the CDC. Symptoms of a listeria infection are fever and muscle aches, sometimes associated with diarrhea or other gastrointestinal symptoms. In the United States, an estimated 1,600 people become seriously ill each year, and approximately 16% of these illnesses result in death. Cervical infections caused by listeriosis in pregnant women may result in stillbirth or spontaneous abortion during the second or third trimesters. CNN's Debra Goldschmidt, Amanda Watts and Jacque Wilson contributed to this report.\n",
"prompt": "Summarize the following news within 161 words:\nBlue Bell ice cream has temporarily shut down one of its manufacturing plants over the discovery of listeria contamination in a serving of ice cream originating from that plant. Public health officials warned consumers Friday not to eat any Blue Bell-branded products made at the company's Broken Arrow, Oklahoma, plant. That includes 3-ounce servings of Blue Bell ice cream from this plant that went to institutions in containers marked with the letters O, P, Q, R, S or T behind the coding date. The warning by the Centers for Disease Control and Prevention does not affect other Blue Bell ice cream, including other 3-ounce servings, not made at the plant. But Blue Bell has recalled other products. The company is shutting down the Broken Arrow facility \"out of an abundance of caution\" to search for a possible cause of contamination. It is the third time Blue Bell has taken action in light of a listeria outbreak at a Kansas hospital that served the company's ice cream. Listeria monocytogenes was recently found in a cup of ice cream recovered from the hospital. The cup contaminated with the bacteria was produced at the Broken Arrow plant in April 2014, Blue Bell said. And, according to the CDC, listeria bacteria was found in additional samples of the same product that were recovered from the plant. The bacteria in the hospital sample and the factory sample appeared to match each other genetically, the CDC said. But they did not appear identical to listeria samples taken from patients infected in the Kansas outbreak. In a separate outbreak in Texas, the CDC did find that listeria samples taken from patients who came down with listeriosis between 2010 and 2014 in a hospital that served 3-ounce Blue Bell cups matched the listeria in recovered samples. None of this means the ice cream is the source of either spate of the infections. \"Investigation to determine whether these illnesses are related to exposure to Blue Bell products is ongoing,\" the CDC said. In early March, in light of the Kansas listeria outbreak, Blue Bell recalled a group of products made at a plant in Texas. It later added 3-ounce cup servings to the recall. Five people were infected and three died in the past year in Kansas from listeria that might be linked to Blue Bell Creameries products, according to the CDC. All five of them were hospitalized at the same hospital before developing listeriosis, the CDC said. At least four of them had consumed milkshakes made with Blue Bell ice cream before developing the infection. \"We are devastated and know that Blue Bell has to be and can be better than this,\" Paul Kruse, Blue Bell CEO and president, said in a statement. \"Quality and safety have always been our top priorities. We are deeply saddened and concerned for all those who have been affected.\" The CDC advises that individuals and institutions should check their freezers for the recalled products and throw them away. In a statement on its website, Blue Bell said \"this recall in no way includes Blue Bell ice cream half gallons, pints, quarts, 3 gallons or other 3 oz. cups.\" This has been the first product recall in the 108-year history of Blue Bell Creameries, the company said. Listeriosis is a serious infection caused by eating food contaminated with listeria, and primarily affects the elderly, pregnant women, newborns and people with weakened immune systems, according to the CDC. Symptoms of a listeria infection are fever and muscle aches, sometimes associated with diarrhea or other gastrointestinal symptoms. In the United States, an estimated 1,600 people become seriously ill each year, and approximately 16% of these illnesses result in death. Cervical infections caused by listeriosis in pregnant women may result in stillbirth or spontaneous abortion during the second or third trimesters. CNN's Debra Goldschmidt, Amanda Watts and Jacque Wilson contributed to this report.\n\noutput:",
"prompt_spans": [
[
0,
46
],
[
47,
556
],
[
539,
1047
],
[
1034,
1539
],
[
1521,
2028
],
[
2012,
2520
],
[
2506,
3017
],
[
3003,
3505
],
[
3488,
3946
],
[
3948,
3955
]
]
}
}
Blue Bell ice cream has temporarily shut down one of its manufacturing plants after discovering listeria contamination in a serving of ice cream produced at the plant. The Centers for Disease Control and Prevention (CDC) has warned consumers not to eat any Blue Bell-branded products made at the Broken Arrow, Oklahoma plant, including 3-ounce servings of ice cream marked with certain codes. This is the third time Blue Bell has taken action due to a listeria outbreak at a Kansas hospital that served the company's ice cream. Investigations into the possible connection between the ice cream and the infections are ongoing. The company has recalled other products and advises individuals and institutions to check their freezers for the recalled items and throw them away. This is the first product recall in Blue Bell's 108-year history.
15599
0.7
Summarize the following news within 161 words:
Blue Bell ice cream has temporarily shut down one of its manufacturing plants over the discovery of listeria contamination in a serving of ice cream originating from that plant. Public health officials warned consumers Friday not to eat any Blue Bell-branded products made at the company's Broken Arrow, Oklahoma, plant. That includes 3-ounce servings of Blue Bell ice cream from this plant that went to institutions in containers marked with the letters O, P, Q, R, S or T behind the coding date. The warning by the Centers for Disease Control and Prevention does not affect other Blue Bell ice cream, including other 3-ounce servings, not made at the plant. But Blue Bell has recalled other products. The company is shutting down the Broken Arrow facility "out of an abundance of caution" to search for a possible cause of contamination. It is the third time Blue Bell has taken action in light of a listeria outbreak at a Kansas hospital that served the company's ice cream. Listeria monocytogenes was recently found in a cup of ice cream recovered from the hospital. The cup contaminated with the bacteria was produced at the Broken Arrow plant in April 2014, Blue Bell said. And, according to the CDC, listeria bacteria was found in additional samples of the same product that were recovered from the plant. The bacteria in the hospital sample and the factory sample appeared to match each other genetically, the CDC said. But they did not appear identical to listeria samples taken from patients infected in the Kansas outbreak. In a separate outbreak in Texas, the CDC did find that listeria samples taken from patients who came down with listeriosis between 2010 and 2014 in a hospital that served 3-ounce Blue Bell cups matched the listeria in recovered samples. None of this means the ice cream is the source of either spate of the infections. "Investigation to determine whether these illnesses are related to exposure to Blue Bell products is ongoing," the CDC said. In early March, in light of the Kansas listeria outbreak, Blue Bell recalled a group of products made at a plant in Texas. It later added 3-ounce cup servings to the recall. Five people were infected and three died in the past year in Kansas from listeria that might be linked to Blue Bell Creameries products, according to the CDC. All five of them were hospitalized at the same hospital before developing listeriosis, the CDC said. At least four of them had consumed milkshakes made with Blue Bell ice cream before developing the infection. "We are devastated and know that Blue Bell has to be and can be better than this," Paul Kruse, Blue Bell CEO and president, said in a statement. "Quality and safety have always been our top priorities. We are deeply saddened and concerned for all those who have been affected." The CDC advises that individuals and institutions should check their freezers for the recalled products and throw them away. In a statement on its website, Blue Bell said "this recall in no way includes Blue Bell ice cream half gallons, pints, quarts, 3 gallons or other 3 oz. cups." This has been the first product recall in the 108-year history of Blue Bell Creameries, the company said. Listeriosis is a serious infection caused by eating food contaminated with listeria, and primarily affects the elderly, pregnant women, newborns and people with weakened immune systems, according to the CDC. Symptoms of a listeria infection are fever and muscle aches, sometimes associated with diarrhea or other gastrointestinal symptoms. In the United States, an estimated 1,600 people become seriously ill each year, and approximately 16% of these illnesses result in death. Cervical infections caused by listeriosis in pregnant women may result in stillbirth or spontaneous abortion during the second or third trimesters. CNN's Debra Goldschmidt, Amanda Watts and Jacque Wilson contributed to this report.
output:
[[0, 46], [47, 556], [539, 1047], [1034, 1539], [1521, 2028], [2012, 2520], [2506, 3017], [3003, 3505], [3488, 3946], [3948, 3955]]
[[0, 506], [491, 840]]
构造模型输入:
1 2 3 4 5 6 7 8 9 10
defadd_special_template(prompt): messages = [ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": prompt} ] text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True) return text
text = add_special_template(prompt[:12000]) print(text)
<s>[INST] <<SYS>>
You are a helpful assistant.
<</SYS>>
Summarize the following news within 161 words:
Blue Bell ice cream has temporarily shut down one of its manufacturing plants over the discovery of listeria contamination in a serving of ice cream originating from that plant. Public health officials warned consumers Friday not to eat any Blue Bell-branded products made at the company's Broken Arrow, Oklahoma, plant. That includes 3-ounce servings of Blue Bell ice cream from this plant that went to institutions in containers marked with the letters O, P, Q, R, S or T behind the coding date. The warning by the Centers for Disease Control and Prevention does not affect other Blue Bell ice cream, including other 3-ounce servings, not made at the plant. But Blue Bell has recalled other products. The company is shutting down the Broken Arrow facility "out of an abundance of caution" to search for a possible cause of contamination. It is the third time Blue Bell has taken action in light of a listeria outbreak at a Kansas hospital that served the company's ice cream. Listeria monocytogenes was recently found in a cup of ice cream recovered from the hospital. The cup contaminated with the bacteria was produced at the Broken Arrow plant in April 2014, Blue Bell said. And, according to the CDC, listeria bacteria was found in additional samples of the same product that were recovered from the plant. The bacteria in the hospital sample and the factory sample appeared to match each other genetically, the CDC said. But they did not appear identical to listeria samples taken from patients infected in the Kansas outbreak. In a separate outbreak in Texas, the CDC did find that listeria samples taken from patients who came down with listeriosis between 2010 and 2014 in a hospital that served 3-ounce Blue Bell cups matched the listeria in recovered samples. None of this means the ice cream is the source of either spate of the infections. "Investigation to determine whether these illnesses are related to exposure to Blue Bell products is ongoing," the CDC said. In early March, in light of the Kansas listeria outbreak, Blue Bell recalled a group of products made at a plant in Texas. It later added 3-ounce cup servings to the recall. Five people were infected and three died in the past year in Kansas from listeria that might be linked to Blue Bell Creameries products, according to the CDC. All five of them were hospitalized at the same hospital before developing listeriosis, the CDC said. At least four of them had consumed milkshakes made with Blue Bell ice cream before developing the infection. "We are devastated and know that Blue Bell has to be and can be better than this," Paul Kruse, Blue Bell CEO and president, said in a statement. "Quality and safety have always been our top priorities. We are deeply saddened and concerned for all those who have been affected." The CDC advises that individuals and institutions should check their freezers for the recalled products and throw them away. In a statement on its website, Blue Bell said "this recall in no way includes Blue Bell ice cream half gallons, pints, quarts, 3 gallons or other 3 oz. cups." This has been the first product recall in the 108-year history of Blue Bell Creameries, the company said. Listeriosis is a serious infection caused by eating food contaminated with listeria, and primarily affects the elderly, pregnant women, newborns and people with weakened immune systems, according to the CDC. Symptoms of a listeria infection are fever and muscle aches, sometimes associated with diarrhea or other gastrointestinal symptoms. In the United States, an estimated 1,600 people become seriously ill each year, and approximately 16% of these illnesses result in death. Cervical infections caused by listeriosis in pregnant women may result in stillbirth or spontaneous abortion during the second or third trimesters. CNN's Debra Goldschmidt, Amanda Watts and Jacque Wilson contributed to this report.
output: [/INST]
构建模型完整的输入输出:
1 2
input_text = text + response_rag print(input_text)
<s>[INST] <<SYS>>
You are a helpful assistant.
<</SYS>>
Summarize the following news within 161 words:
Blue Bell ice cream has temporarily shut down one of its manufacturing plants over the discovery of listeria contamination in a serving of ice cream originating from that plant. Public health officials warned consumers Friday not to eat any Blue Bell-branded products made at the company's Broken Arrow, Oklahoma, plant. That includes 3-ounce servings of Blue Bell ice cream from this plant that went to institutions in containers marked with the letters O, P, Q, R, S or T behind the coding date. The warning by the Centers for Disease Control and Prevention does not affect other Blue Bell ice cream, including other 3-ounce servings, not made at the plant. But Blue Bell has recalled other products. The company is shutting down the Broken Arrow facility "out of an abundance of caution" to search for a possible cause of contamination. It is the third time Blue Bell has taken action in light of a listeria outbreak at a Kansas hospital that served the company's ice cream. Listeria monocytogenes was recently found in a cup of ice cream recovered from the hospital. The cup contaminated with the bacteria was produced at the Broken Arrow plant in April 2014, Blue Bell said. And, according to the CDC, listeria bacteria was found in additional samples of the same product that were recovered from the plant. The bacteria in the hospital sample and the factory sample appeared to match each other genetically, the CDC said. But they did not appear identical to listeria samples taken from patients infected in the Kansas outbreak. In a separate outbreak in Texas, the CDC did find that listeria samples taken from patients who came down with listeriosis between 2010 and 2014 in a hospital that served 3-ounce Blue Bell cups matched the listeria in recovered samples. None of this means the ice cream is the source of either spate of the infections. "Investigation to determine whether these illnesses are related to exposure to Blue Bell products is ongoing," the CDC said. In early March, in light of the Kansas listeria outbreak, Blue Bell recalled a group of products made at a plant in Texas. It later added 3-ounce cup servings to the recall. Five people were infected and three died in the past year in Kansas from listeria that might be linked to Blue Bell Creameries products, according to the CDC. All five of them were hospitalized at the same hospital before developing listeriosis, the CDC said. At least four of them had consumed milkshakes made with Blue Bell ice cream before developing the infection. "We are devastated and know that Blue Bell has to be and can be better than this," Paul Kruse, Blue Bell CEO and president, said in a statement. "Quality and safety have always been our top priorities. We are deeply saddened and concerned for all those who have been affected." The CDC advises that individuals and institutions should check their freezers for the recalled products and throw them away. In a statement on its website, Blue Bell said "this recall in no way includes Blue Bell ice cream half gallons, pints, quarts, 3 gallons or other 3 oz. cups." This has been the first product recall in the 108-year history of Blue Bell Creameries, the company said. Listeriosis is a serious infection caused by eating food contaminated with listeria, and primarily affects the elderly, pregnant women, newborns and people with weakened immune systems, according to the CDC. Symptoms of a listeria infection are fever and muscle aches, sometimes associated with diarrhea or other gastrointestinal symptoms. In the United States, an estimated 1,600 people become seriously ill each year, and approximately 16% of these illnesses result in death. Cervical infections caused by listeriosis in pregnant women may result in stillbirth or spontaneous abortion during the second or third trimesters. CNN's Debra Goldschmidt, Amanda Watts and Jacque Wilson contributed to this report.
output: [/INST]Blue Bell ice cream has temporarily shut down one of its manufacturing plants after discovering listeria contamination in a serving of ice cream produced at the plant. The Centers for Disease Control and Prevention (CDC) has warned consumers not to eat any Blue Bell-branded products made at the Broken Arrow, Oklahoma plant, including 3-ounce servings of ice cream marked with certain codes. This is the third time Blue Bell has taken action due to a listeria outbreak at a Kansas hospital that served the company's ice cream. Investigations into the possible connection between the ice cream and the infections are ongoing. The company has recalled other products and advises individuals and institutions to check their freezers for the recalled items and throw them away. This is the first product recall in Blue Bell's 108-year history.
torch.Size([1, 32, 1189, 1189])
torch.Size([1, 1189, 1189])
[[[22, 37], 0.11279296875], [[37, 155], 4.30078125], [[151, 275], 1.498046875], [[270, 390], 0.69775390625], [[387, 513], 0.25341796875], [[507, 629], 0.27685546875], [[626, 740], 0.76806640625], [[737, 875], 1.3994140625], [[869, 987], 6.05078125], [[987, 991], 0.0654296875]]
and muscle aches, sometimes associated with diarrhea or other gastrointestinal symptoms. In the United States, an estimated 1,600 people become seriously ill each year, and approximately 16% of these illnesses result in death. Cervical infections caused by listeriosis in pregnant women may result in stillbirth or spontaneous abortion during the second or third trimesters. CNN's Debra Goldschmidt, Amanda Watts and Jacque Wilson contributed to this report.
that served the company's ice cream. Investigations into the possible connection between the ice cream and the infections are ongoing. The company has recalled other products and advises individuals and institutions to check their freezers for the recalled items and throw them away. This is the first product recall in Blue Bell's 108-year history.
{'(1, 14)': 0.7934820652008057, '(1, 21)': 0.5256378650665283, '(1, 27)': 0.7934820652008057, '(2, 5)': 0.5256378650665283, '(2, 22)': 0.5256378650665283, '(3, 0)': 0.5256378650665283, '(3, 19)': 0.5256378650665283, '(5, 13)': 0.5256378650665283, '(5, 29)': 0.5256378650665283, '(10, 20)': 0.5256378650665283, '(13, 20)': 0.5256378650665283, '(15, 7)': 0.5256378650665283, '(16, 1)': 0.7934820652008057, '(18, 9)': 0.7934820652008057, '(18, 10)': 0.7934820652008057, '(18, 13)': 0.5256378650665283, '(19, 1)': 0.5256378650665283, '(20, 1)': 0.7861142158508301, '(20, 5)': 0.7861142158508301, '(20, 15)': 0.5256378650665283, '(20, 17)': 0.7934820652008057, '(20, 22)': 0.5256378650665283, '(22, 10)': 0.5256378650665283, '(23, 8)': 0.7861142158508301, '(23, 30)': 0.5256378650665283, '(25, 0)': 0.7861142158508301, '(27, 9)': 0.5256378650665283, '(28, 18)': 0.5256378650665283, '(31, 18)': 0.5256378650665283, '(31, 19)': 0.5256378650665283, '(31, 24)': 0.7118228077888489, '(31, 28)': 0.5256378650665283}
kl1 = F.kl_div(log_softmax_mature_layer, M, reduction='none').sum(dim=-1) kl2 = F.kl_div(log_softmax_anchor_layer, M, reduction='none').sum(dim=-1) js_divs = 0.5 * (kl1 + kl2)
scores = js_divs.cpu().tolist() # 换成了散度的和
returnsum(scores)
幻觉片段判断函数:
1 2 3 4 5 6
defis_hallucination_span(r_span, hallucination_spans): for token_id inrange(r_span[0], r_span[1]): for span in hallucination_spans: if token_id >= span[0] and token_id <= span[1]: returnTrue returnFalse
计算 PKS:
1 2 3 4 5 6 7 8 9 10 11 12
for r_id, r_span inenumerate(respond_spans): parameter_knowledge_scores = [calculate_dist_2d(value[0][0,r_span[0]:r_span[1],:], value[1][0,r_span[0]:r_span[1],:]) for value in logits_dict.values()] parameter_knowledge_dict = {f"layer_{i}": value for i, value inenumerate(parameter_knowledge_scores)}
[
{
"id": "45",
"source_id": "15599",
"model": "llama-2-7b-chat",
"temperature": 0.7,
"labels": [],
"split": "test",
"quality": "good",
"response": "Blue Bell ice cream has temporarily shut down one of its manufacturing plants after discovering listeria contamination in a serving of ice cream produced at the plant. The Centers for Disease Control and Prevention (CDC) has warned consumers not to eat any Blue Bell-branded products made at the Broken Arrow, Oklahoma plant, including 3-ounce servings of ice cream marked with certain codes. This is the third time Blue Bell has taken action due to a listeria outbreak at a Kansas hospital that served the company's ice cream. Investigations into the possible connection between the ice cream and the infections are ongoing. The company has recalled other products and advises individuals and institutions to check their freezers for the recalled items and throw them away. This is the first product recall in Blue Bell's 108-year history.",
"response_spans": [
[
0,
506
],
[
491,
840
]
],
"scores": [
{
"prompt_attention_score": {
"(1, 14)": 0.7934820652008057,
"(1, 21)": 0.5256378650665283,
"(1, 27)": 0.7934820652008057,
"(2, 5)": 0.5256378650665283,
"(2, 22)": 0.5256378650665283,
"(3, 0)": 0.5256378650665283,
"(3, 19)": 0.5256378650665283,
"(5, 13)": 0.5256378650665283,
"(5, 29)": 0.5256378650665283,
"(10, 20)": 0.5256378650665283,
"(13, 20)": 0.5256378650665283,
"(15, 7)": 0.5256378650665283,
"(16, 1)": 0.7934820652008057,
"(18, 9)": 0.7934820652008057,
"(18, 10)": 0.7934820652008057,
"(18, 13)": 0.5256378650665283,
"(19, 1)": 0.5256378650665283,
"(20, 1)": 0.7861142158508301,
"(20, 5)": 0.7861142158508301,
"(20, 15)": 0.5256378650665283,
"(20, 17)": 0.7934820652008057,
"(20, 22)": 0.5256378650665283,
"(22, 10)": 0.5256378650665283,
"(23, 8)": 0.7861142158508301,
"(23, 30)": 0.5256378650665283,
"(25, 0)": 0.7861142158508301,
"(27, 9)": 0.5256378650665283,
"(28, 18)": 0.5256378650665283,
"(31, 18)": 0.5256378650665283,
"(31, 19)": 0.5256378650665283,
"(31, 24)": 0.7118228077888489,
"(31, 28)": 0.5256378650665283
},
"r_span": [
995,
1114
],
"hallucination_label": 0,
"parameter_knowledge_scores": {
"layer_0": 10.039642333984375,
"layer_1": 19.6171875,
"layer_2": 13.364913940429688,
"layer_3": 15.792007446289062,
"layer_4": 16.167789459228516,
"layer_5": 14.672402381896973,
"layer_6": 14.83043384552002,
"layer_7": 16.115909576416016,
"layer_8": 14.244064331054688,
"layer_9": 13.896240234375,
"layer_10": 13.285934448242188,
"layer_11": 11.34033203125,
"layer_12": 10.39111328125,
"layer_13": 9.857498168945312,
"layer_14": 9.97247314453125,
"layer_15": 9.715774536132812,
"layer_16": 9.486862182617188,
"layer_17": 7.691881537437439,
"layer_18": 11.035508871078491,
"layer_19": 8.649388074874878,
"layer_20": 7.8278902769088745,
"layer_21": 4.75305837392807,
"layer_22": 4.245644927024841,
"layer_23": 6.389559030532837,
"layer_24": 15.33685153722763,
"layer_25": 2.7393543124198914,
"layer_26": 2.4489996433258057,
"layer_27": 1.971637487411499,
"layer_28": 5.669117510318756,
"layer_29": 2.5789473056793213,
"layer_30": 7.760132610797882,
"layer_31": 6.783948659896851
}
},
{
"prompt_attention_score": {
"(1, 14)": 0.7934820652008057,
"(1, 21)": 0.5256378650665283,
"(1, 27)": 0.7934820652008057,
"(2, 5)": 0.5256378650665283,
"(2, 22)": 0.5256378650665283,
"(3, 0)": 0.5256378650665283,
"(3, 19)": 0.5256378650665283,
"(5, 13)": 0.5256378650665283,
"(5, 29)": 0.5256378650665283,
"(10, 20)": 0.5256378650665283,
"(13, 20)": 0.5256378650665283,
"(15, 7)": 0.5256378650665283,
"(16, 1)": 0.7934820652008057,
"(18, 9)": 0.7934820652008057,
"(18, 10)": 0.7934820652008057,
"(18, 13)": 0.5256378650665283,
"(19, 1)": 0.5256378650665283,
"(20, 1)": 0.7861142158508301,
"(20, 5)": 0.7861142158508301,
"(20, 15)": 0.5256378650665283,
"(20, 17)": 0.7934820652008057,
"(20, 22)": 0.5256378650665283,
"(22, 10)": 0.5256378650665283,
"(23, 8)": 0.7861142158508301,
"(23, 30)": 0.5256378650665283,
"(25, 0)": 0.7861142158508301,
"(27, 9)": 0.5256378650665283,
"(28, 18)": 0.5256378650665283,
"(31, 18)": 0.5256378650665283,
"(31, 19)": 0.5256378650665283,
"(31, 24)": 0.7118228077888489,
"(31, 28)": 0.5256378650665283
},
"r_span": [
1112,
1189
],
"hallucination_label": 0,
"parameter_knowledge_scores": {
"layer_0": 6.265625,
"layer_1": 11.825347900390625,
"layer_2": 7.304943084716797,
"layer_3": 8.502777099609375,
"layer_4": 8.751604080200195,
"layer_5": 9.063507080078125,
"layer_6": 10.59210205078125,
"layer_7": 10.3037109375,
"layer_8": 9.185203552246094,
"layer_9": 8.613269805908203,
"layer_10": 8.374945402145386,
"layer_11": 6.96978759765625,
"layer_12": 7.036556243896484,
"layer_13": 6.907812118530273,
"layer_14": 6.779157400131226,
"layer_15": 6.831340312957764,
"layer_16": 5.449123382568359,
"layer_17": 7.206271290779114,
"layer_18": 4.6526288986206055,
"layer_19": 5.492448091506958,
"layer_20": 4.489939272403717,
"layer_21": 3.39082270860672,
"layer_22": 2.022574782371521,
"layer_23": 1.9388360977172852,
"layer_24": 4.99117386341095,
"layer_25": 15.26219892501831,
"layer_26": 6.535698175430298,
"layer_27": 6.107271254062653,
"layer_28": 3.5565916895866394,
"layer_29": 1.0493692755699158,
"layer_30": 4.485132694244385,
"layer_31": 5.870414137840271
}
}
]
}
]
保存结果:
1 2
withopen("../output/llama2_7B_response_chunk.json", "w") as f: json.dump(select_response, f, ensure_ascii=False)
2.3 regress.py
2.3.1 token 级别
导入必要的包:
1 2 3 4 5 6 7 8 9 10
import pandas as pd import json import argparse from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import classification_report from sklearn.metrics import roc_auc_score from scipy.stats import pearsonr from sklearn.preprocessing import MinMaxScaler from sklearn.metrics import accuracy_score
# 定义表头:索引、ECS、PKS、幻觉标签 data_dict = { "identifier": [], **{f"external_similarity_{k}": [] for k inrange(number)}, **{f"parameter_knowledge_difference_{k}": [] for k inrange(number)}, "hallucination_label": [] }
# response_i 表示第 i 个 response,item_j 表示第 j 个 token ID for i, resp inenumerate(response): # 遍历每个 response if resp["split"] != "test": continue for j inrange(len(resp["external_similarity"])): # 遍历每个 token ID data_dict["identifier"].append(f"response_{i}_item_{j}") for k inrange(number): # 遍历每个具体的得分 data_dict[f"external_similarity_{k}"].append(resp["external_similarity"][j][k]) data_dict[f"parameter_knowledge_difference_{k}"].append(resp["parameter_knowledge_difference"][j][k]) data_dict["hallucination_label"].append(resp["hallucination_label"][j])
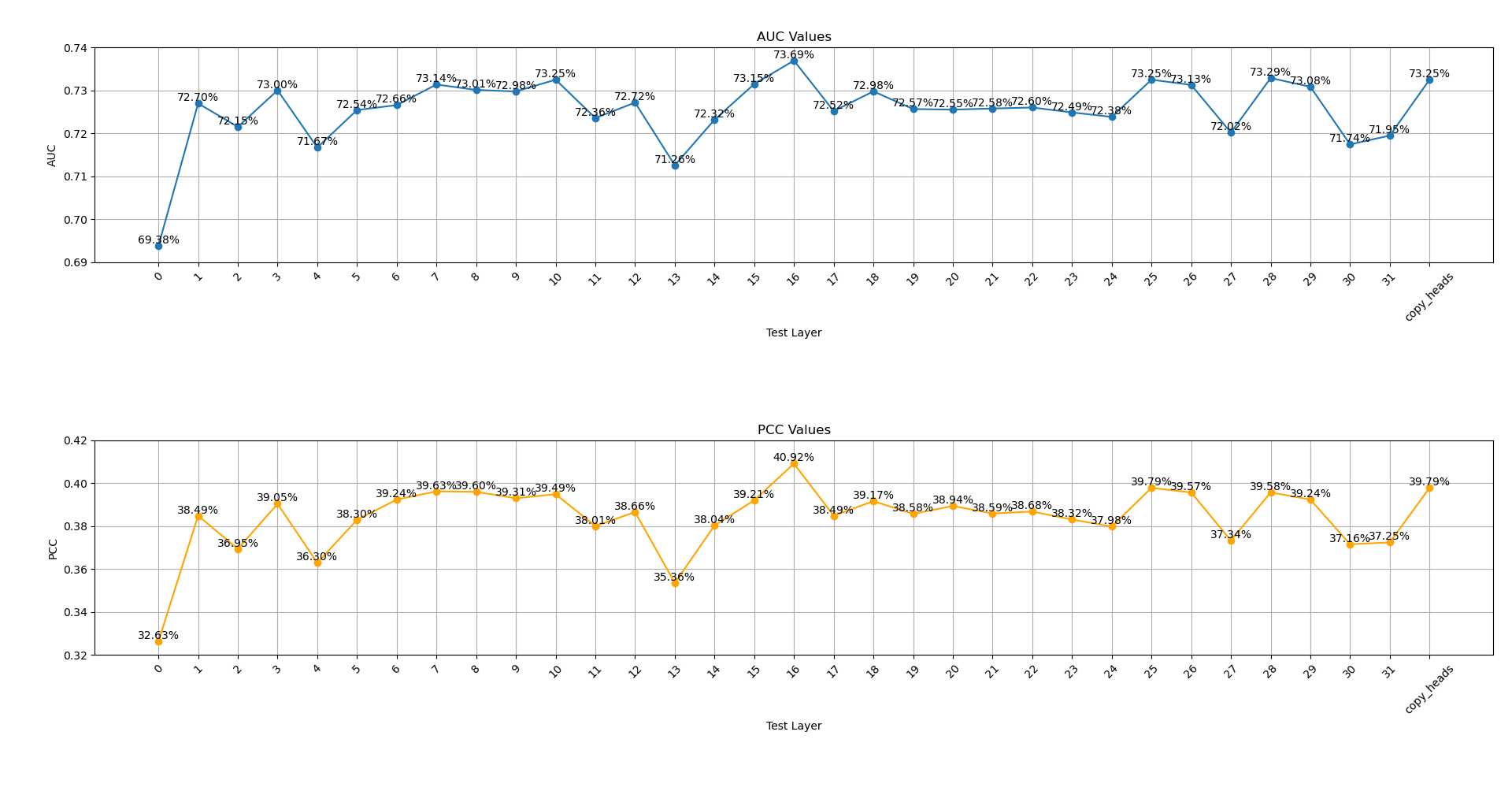
# 选择 PKS 的 AUC 分数最高的 top_k 个特征 top_auc_parameter_knowledge_difference = sorted(auc_parameter_knowledge_difference, reverse=True)[:top_k] print(top_auc_parameter_knowledge_difference) base_layer = 0 collect_info.update({"select_layers": [eval(name.split('_')[-1]) + base_layer for _, name in top_auc_parameter_knowledge_difference]})
# 对于选择好的特征,求其对应 df 列的和,表示为 ECS 和 PKS 的和 df['external_similarity_sum'] = df[[col for _, col in top_auc_external_similarity]].sum(axis=1) df['parameter_knowledge_difference_sum'] = df[[col for _, col in top_auc_parameter_knowledge_difference]].sum(axis=1)
save_path = "../output/ReDeEP_token.json" withopen(save_path, 'w') as f: json.dump(result_dict, f, ensure_ascii=False)
2.3.2 chunk 级别
导入必要的包:
1 2 3 4 5 6 7 8 9
import pandas as pd import json from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import classification_report from sklearn.metrics import roc_auc_score from scipy.stats import pearsonr from sklearn.preprocessing import MinMaxScaler from sklearn.metrics import accuracy_score
defconstruct_dataframe(file_path, number): withopen(file_path, "r") as f: response = json.load(f)
data_dict = { "identifier": [], "type":[], # 任务类型 **{f"external_similarity_{k}": [] for k inrange(number)}, **{f"parameter_knowledge_difference_{k}": [] for k inrange(number)}, "hallucination_label": [] }
for i, resp inenumerate(response): # 遍历每个 response if resp["split"] != "test": continue respond_ids = resp["source_id"] rep_type = source_info_dict[respond_ids]["task_type"] # 获取任务类型
for j inrange(len(resp["scores"])): # 遍历每个 response 片段 data_dict["identifier"].append(f"response_{i}_item_{j}") data_dict["type"].append(rep_type) for k inrange(number): data_dict[f"external_similarity_{k}"].append(list(resp["scores"][j]["prompt_attention_score"].values())[k]) data_dict[f"parameter_knowledge_difference_{k}"].append(list(resp["scores"][j]["parameter_knowledge_scores"].values())[k]) data_dict["hallucination_label"].append(resp["scores"][j]["hallucination_label"]) if i == len(response)-1: # 记录 copy_heads 和 layers ext_map_dict = {f"external_similarity_{k}":list(resp["scores"][j]["prompt_attention_score"].keys())[k] for k inrange(number)} para_map_dict = {f"parameter_knowledge_difference_{k}":list(resp["scores"][j]["parameter_knowledge_scores"].keys())[k] for k inrange(number)}
# 把表头换成对应的 copy_heads 或 layers auc_external_similarity_rename = [[a, ext_map_dict[k]] for a, k in auc_external_similarity] auc_parameter_knowledge_difference_rename = [[a, para_map_dict[k]] for a, k in auc_parameter_knowledge_difference]
df['external_similarity_sum'] = df[[col for _, col in top_auc_external_similarity]].sum(axis=1) df['parameter_knowledge_difference_sum'] = df[[col for _, col in top_auc_parameter_knowledge_difference]].sum(axis=1)
i, j, k, m = 3, 4, 0.6, 1 auc_difference_normalized, person_difference_normalized = calculate_auc_pcc_32_32(df, i, j, k, auc_external_similarity, auc_parameter_knowledge_difference, m)
{
"15596": {
"source_id": "15596",
"task_type": "Summary",
"source": "CNN/DM",
"source_info": "The FBI charged a Philadelphia woman on Thursday with trying to travel overseas to fight for ISIS. She's one of three women arrested this week on terror charges. Two New York women were also taken into custody. An FBI complaint cites numerous social media messages dating back to August 2013 that were sent by Keonna Thomas, 30, also known as \"Young Lioness\" and \"Fatayat Al Khilafah.\" One Twitter message said, \"If we truly knew the realities ... we all would be rushing to join our brothers in the front lines pray ALLAH accept us as shuhada [martyrs].\" Another said, \"When you're a mujahid [violent jihadi fighter] your death becomes a wedding.\" The FBI said Thomas purchased an electronic visa to Turkey on March 23. Turkey is known as the easiest place from which to enter Syria and join ISIS. An ISIS manual advises recruits to buy round-trip tickets to vacation spots such as Spain and then purchase tickets for their real destination once they arrive overseas, the FBI said. On March 26, Thomas purchased a ticket to Barcelona, with a March 29 departure and an April 15 return to the United States, the complaint said. It's not clear when or where she was arrested. She was charged with knowingly attempting to provide material support and resources to a designated foreign terrorist organization. She could be sentenced to 15 years in prison. On Thursday, Noelle Velentzas, 28, and her former roommate, Asia Siddiqui, 31, were arrested in New York and accused of planning to build an explosive device for attacks in the United States, federal prosecutors said. In the past 18 months, the Justice Department's National Security Division has prosecuted or is prosecuting more than 30 cases of people attempting to travel abroad to join or provide support to terrorist groups. Of those cases, 18 allegedly involve support to ISIS. \"The terrorist threat is more decentralized, more diffuse, more complicated,\" Homeland Security Secretary Jeh Johnson told reporters Thursday. \"It involves the potential lone wolf actor, it involves the effective use of social media, the Internet.\"\n",
"prompt": "Summarize the following news within 86 words:\nThe FBI charged a Philadelphia woman on Thursday with trying to travel overseas to fight for ISIS. She's one of three women arrested this week on terror charges. Two New York women were also taken into custody. An FBI complaint cites numerous social media messages dating back to August 2013 that were sent by Keonna Thomas, 30, also known as \"Young Lioness\" and \"Fatayat Al Khilafah.\" One Twitter message said, \"If we truly knew the realities ... we all would be rushing to join our brothers in the front lines pray ALLAH accept us as shuhada [martyrs].\" Another said, \"When you're a mujahid [violent jihadi fighter] your death becomes a wedding.\" The FBI said Thomas purchased an electronic visa to Turkey on March 23. Turkey is known as the easiest place from which to enter Syria and join ISIS. An ISIS manual advises recruits to buy round-trip tickets to vacation spots such as Spain and then purchase tickets for their real destination once they arrive overseas, the FBI said. On March 26, Thomas purchased a ticket to Barcelona, with a March 29 departure and an April 15 return to the United States, the complaint said. It's not clear when or where she was arrested. She was charged with knowingly attempting to provide material support and resources to a designated foreign terrorist organization. She could be sentenced to 15 years in prison. On Thursday, Noelle Velentzas, 28, and her former roommate, Asia Siddiqui, 31, were arrested in New York and accused of planning to build an explosive device for attacks in the United States, federal prosecutors said. In the past 18 months, the Justice Department's National Security Division has prosecuted or is prosecuting more than 30 cases of people attempting to travel abroad to join or provide support to terrorist groups. Of those cases, 18 allegedly involve support to ISIS. \"The terrorist threat is more decentralized, more diffuse, more complicated,\" Homeland Security Secretary Jeh Johnson told reporters Thursday. \"It involves the potential lone wolf actor, it involves the effective use of social media, the Internet.\"\n\noutput:"
}
}
获取 reponse 的 source_id:
1 2 3 4 5 6 7 8 9 10 11
source_id_list = []
response_path = "../dataset/response.jsonl"
withopen(response_path, 'r') as f: for line in f: data = json.loads(line) if data["split"] == "test": source_id_list.append(data["source_id"])
{
"15596": {
"source_id": "15596",
"task_type": "Summary",
"source": "CNN/DM",
"source_info": "The FBI charged a Philadelphia woman on Thursday with trying to travel overseas to fight for ISIS. She's one of three women arrested this week on terror charges. Two New York women were also taken into custody. An FBI complaint cites numerous social media messages dating back to August 2013 that were sent by Keonna Thomas, 30, also known as \"Young Lioness\" and \"Fatayat Al Khilafah.\" One Twitter message said, \"If we truly knew the realities ... we all would be rushing to join our brothers in the front lines pray ALLAH accept us as shuhada [martyrs].\" Another said, \"When you're a mujahid [violent jihadi fighter] your death becomes a wedding.\" The FBI said Thomas purchased an electronic visa to Turkey on March 23. Turkey is known as the easiest place from which to enter Syria and join ISIS. An ISIS manual advises recruits to buy round-trip tickets to vacation spots such as Spain and then purchase tickets for their real destination once they arrive overseas, the FBI said. On March 26, Thomas purchased a ticket to Barcelona, with a March 29 departure and an April 15 return to the United States, the complaint said. It's not clear when or where she was arrested. She was charged with knowingly attempting to provide material support and resources to a designated foreign terrorist organization. She could be sentenced to 15 years in prison. On Thursday, Noelle Velentzas, 28, and her former roommate, Asia Siddiqui, 31, were arrested in New York and accused of planning to build an explosive device for attacks in the United States, federal prosecutors said. In the past 18 months, the Justice Department's National Security Division has prosecuted or is prosecuting more than 30 cases of people attempting to travel abroad to join or provide support to terrorist groups. Of those cases, 18 allegedly involve support to ISIS. \"The terrorist threat is more decentralized, more diffuse, more complicated,\" Homeland Security Secretary Jeh Johnson told reporters Thursday. \"It involves the potential lone wolf actor, it involves the effective use of social media, the Internet.\"\n",
"prompt": "Summarize the following news within 86 words:\nThe FBI charged a Philadelphia woman on Thursday with trying to travel overseas to fight for ISIS. She's one of three women arrested this week on terror charges. Two New York women were also taken into custody. An FBI complaint cites numerous social media messages dating back to August 2013 that were sent by Keonna Thomas, 30, also known as \"Young Lioness\" and \"Fatayat Al Khilafah.\" One Twitter message said, \"If we truly knew the realities ... we all would be rushing to join our brothers in the front lines pray ALLAH accept us as shuhada [martyrs].\" Another said, \"When you're a mujahid [violent jihadi fighter] your death becomes a wedding.\" The FBI said Thomas purchased an electronic visa to Turkey on March 23. Turkey is known as the easiest place from which to enter Syria and join ISIS. An ISIS manual advises recruits to buy round-trip tickets to vacation spots such as Spain and then purchase tickets for their real destination once they arrive overseas, the FBI said. On March 26, Thomas purchased a ticket to Barcelona, with a March 29 departure and an April 15 return to the United States, the complaint said. It's not clear when or where she was arrested. She was charged with knowingly attempting to provide material support and resources to a designated foreign terrorist organization. She could be sentenced to 15 years in prison. On Thursday, Noelle Velentzas, 28, and her former roommate, Asia Siddiqui, 31, were arrested in New York and accused of planning to build an explosive device for attacks in the United States, federal prosecutors said. In the past 18 months, the Justice Department's National Security Division has prosecuted or is prosecuting more than 30 cases of people attempting to travel abroad to join or provide support to terrorist groups. Of those cases, 18 allegedly involve support to ISIS. \"The terrorist threat is more decentralized, more diffuse, more complicated,\" Homeland Security Secretary Jeh Johnson told reporters Thursday. \"It involves the potential lone wolf actor, it involves the effective use of social media, the Internet.\"\n\noutput:"
}
}
0%| | 0/1 [00:00<?, ?it/s]
input_ids torch.Size([1, 564])
100%|██████████| 1/1 [00:07<00:00, 7.60s/it]
FBI charges Philadelphia woman, Keonna Thomas, with attempting to provide material support to ISIS. She purchased an electronic visa to Turkey and had social media messages expressing desire to join ISIS. Two other women were arrested in New York on similar charges. The FBI has prosecuted or is prosecuting over 30 cases of people attempting to travel abroad to join or provide support to terrorist groups, with 18 involving ISIS.
保存并查看结果:
1 2 3
withopen(f"../output/AARF_add_{model.add_attention_weight}_reduce_{model.reduce_ffn_weight}_threshold_{model.threshold}.json", "w") as f: json.dump(final_datas, f, indent=4, ensure_ascii=False) final_datas
[{'id': '15596',
'prompt': 'Summarize the following news within 86 words:\nThe FBI charged a Philadelphia woman on Thursday with trying to travel overseas to fight for ISIS. She\'s one of three women arrested this week on terror charges. Two New York women were also taken into custody. An FBI complaint cites numerous social media messages dating back to August 2013 that were sent by Keonna Thomas, 30, also known as "Young Lioness" and "Fatayat Al Khilafah." One Twitter message said, "If we truly knew the realities ... we all would be rushing to join our brothers in the front lines pray ALLAH accept us as shuhada [martyrs]." Another said, "When you\'re a mujahid [violent jihadi fighter] your death becomes a wedding." The FBI said Thomas purchased an electronic visa to Turkey on March 23. Turkey is known as the easiest place from which to enter Syria and join ISIS. An ISIS manual advises recruits to buy round-trip tickets to vacation spots such as Spain and then purchase tickets for their real destination once they arrive overseas, the FBI said. On March 26, Thomas purchased a ticket to Barcelona, with a March 29 departure and an April 15 return to the United States, the complaint said. It\'s not clear when or where she was arrested. She was charged with knowingly attempting to provide material support and resources to a designated foreign terrorist organization. She could be sentenced to 15 years in prison. On Thursday, Noelle Velentzas, 28, and her former roommate, Asia Siddiqui, 31, were arrested in New York and accused of planning to build an explosive device for attacks in the United States, federal prosecutors said. In the past 18 months, the Justice Department\'s National Security Division has prosecuted or is prosecuting more than 30 cases of people attempting to travel abroad to join or provide support to terrorist groups. Of those cases, 18 allegedly involve support to ISIS. "The terrorist threat is more decentralized, more diffuse, more complicated," Homeland Security Secretary Jeh Johnson told reporters Thursday. "It involves the potential lone wolf actor, it involves the effective use of social media, the Internet."\n\noutput:',
'response': ' FBI charges Philadelphia woman, Keonna Thomas, with attempting to provide material support to ISIS. She purchased an electronic visa to Turkey and had social media messages expressing desire to join ISIS. Two other women were arrested in New York on similar charges. The FBI has prosecuted or is prosecuting over 30 cases of people attempting to travel abroad to join or provide support to terrorist groups, with 18 involving ISIS.'}]