templates_for_qa = [ "Question: {question}?\nAnswer:", "{question}?", "Answer the following question:\n\n{question}", "Answer this question:\n\n{question}?", "Please answer this question: {question}", "Answer the question...{question}?", "What is the answer to this question? {question}\n\n", "Can you tell me the answer to {question}?", "Next question: {question}\n\n", "Q: {question} A:", "{question}\nWhat is the answer?", "Write the answer: {question}", "{question}???", ]
templates_for_sum = [ "Write a short summary for the text\n\nSummary:", "Briefly summarize this article:\nSummary:", "What is a shorter version of this:\n\nSummary:", "Write a brief summary in a sentence or less.", "What is a very short summary of the above text?", "Summarize the aforementioned text in a single phrase.", "Can you generate a short summary of the above paragraph?", "Summarize the above articles\n\ntl;dr:", ]
template_for_fact_checking = [ "Verify the following claims with \"True\" or \"False\":\n{question}", ]
3 示例
3.1 准备工作
导入必要的包:
1 2 3 4 5
import torch import torch.nn as nn import re from torch import Tensor from transformers import AutoTokenizer, MistralForCausalLM, MistralModel
Loading checkpoint shards: 100%|██████████| 3/3 [00:00<00:00, 5.52it/s]
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
question = """What company advertised itself with the slogan "We'll leave a light on for you"?"""# 哪家公司用“我们会为您留下一盏灯”的口号来宣传自己(答案是“Motel 6”) template = "[INST] Answer the questions:\n\nQuestion: {question} [/INST] The answer is:" prompt = template.format_map(dict(question=question)) # format_map将问题插入到模板 print(prompt)
[INST] Answer the questions:
Question: What company advertised itself with the slogan "We'll leave a light on for you"? [/INST] The answer is:
CPU times: user 28.6 s, sys: 1.37 s, total: 29.9 s
Wall time: 30 s
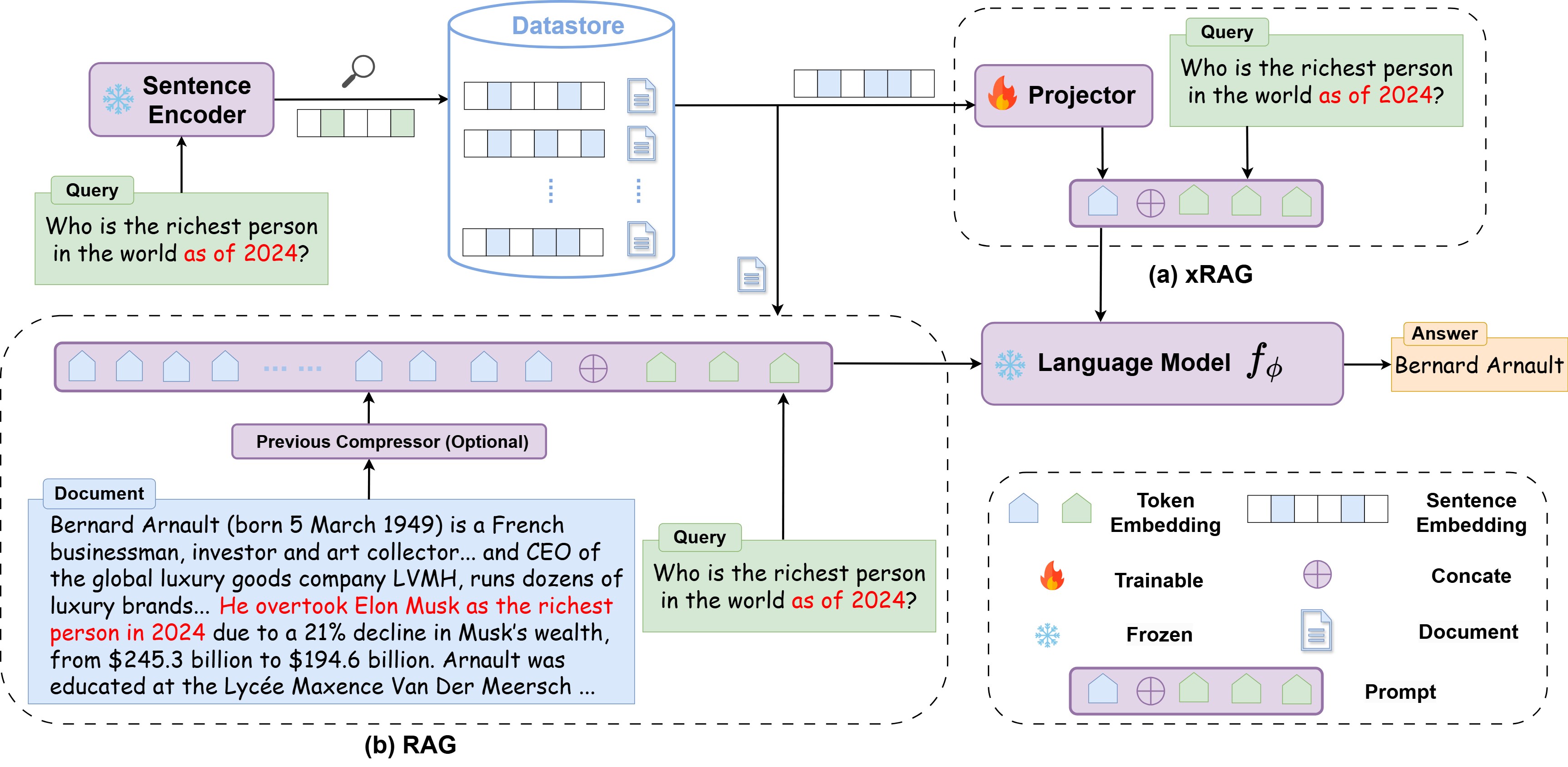
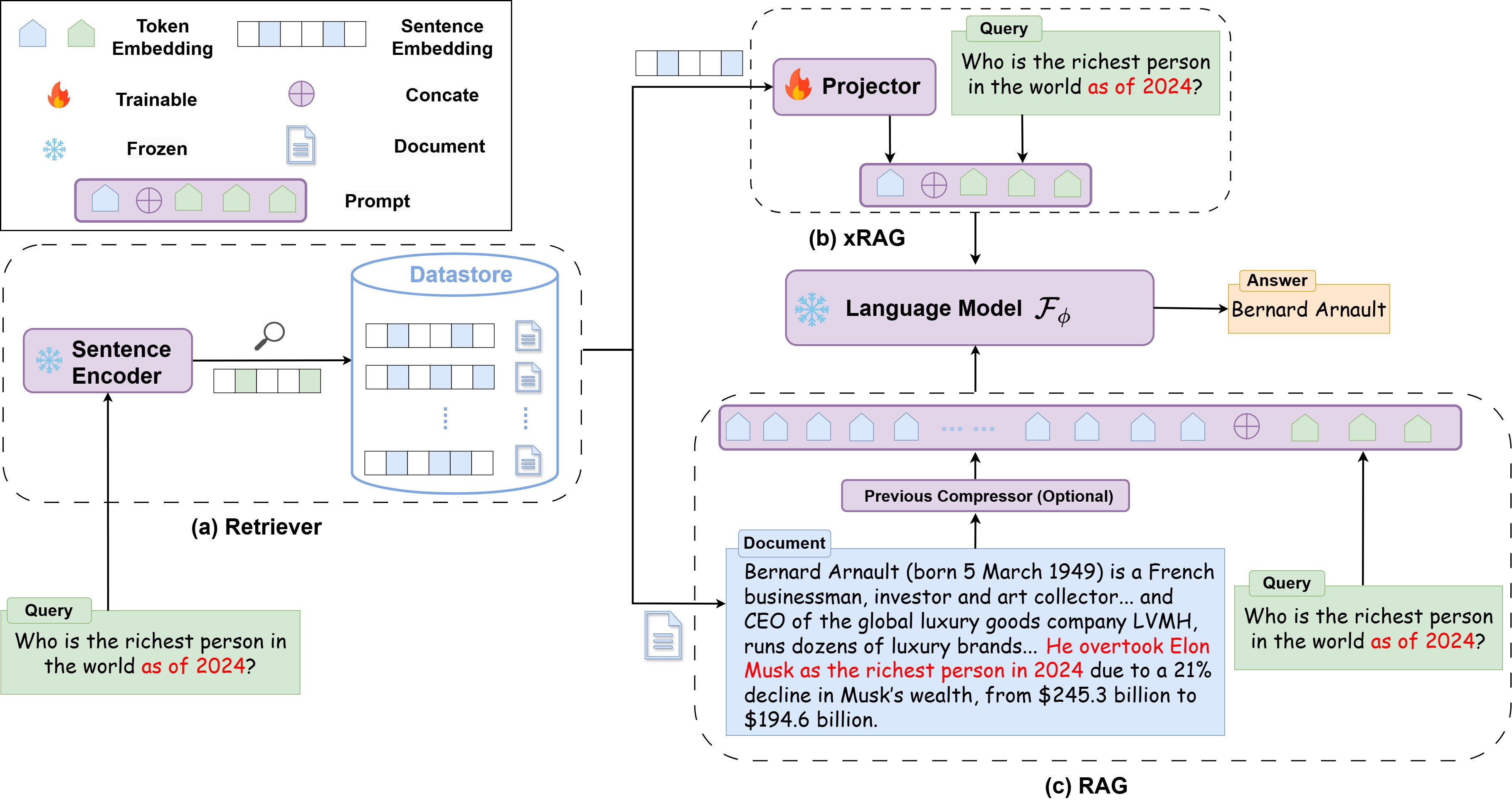
3.3 传统 RAG
模拟数据库:
1 2 3 4 5 6 7
documents = [ 'Alvin and the Chipmunks | " Alvin and the Chipmunks, originally David Seville and the Chipmunks or simply The Chipmunks, are an American animated virtual band created by Ross Bagdasarian for a novelty record in 1958. The group consists of three singing animated anthropomorphic chipmunks named Alvin, Simon, and Theodore. They are managed by their human adoptive father, David ""Dave"" Seville. Bagdasarian provided the group\'s voices sped up to create high-pitched squeaky voices (which wasn\'t entirely new to him, having worked on ""Witch Doctor"" earned the record two Grammy Awards for engineering). ""The Chipmunk Song"" became a number-one single in the United States. After Bagdasarian died in 1972, the characters’ voices were provided by his son Ross Bagdasarian Jr. and the latter\'s wife Janice Karman in the subsequent incarnations of "', "Jamie Lee Curtis | Jamie Lee Curtis (born November 22, 1958) is an American actress and writer. She is the recipient of several accolades, including a British Academy Film Award, two Golden Globe Awards and a star on the Hollywood Walk of Fame in 1998. Curtis made her film acting debut as Laurie Strode in John Carpenter's horror film Halloween (1978), which established her as a scream queen, and she thereafter appeared in a string of horror films, including The Fog, Prom Night, Terror Train (all 1980) and Roadgames (1981). She reprised the role of Laurie in the sequels Halloween II (1981), Halloween H20: 20 Years Later (1998), Halloween: Resurrection (2002), Halloween (2018), and Halloween Kills (2021). Her filmography is largely characterized by independent film that have been box-office successes, with 8 of her lead-actress credits ", 'Sunset Boulevard (musical) | " The American premiere was at the Shubert Theatre in Century City, Los Angeles, California, on 9 December 1993, with Close as Norma and Alan Campbell as Joe. Featured were George Hearn as Max and Judy Kuhn as Betty. Lloyd Webber had reworked both the book and score, tightening the production, better organising the orchestrations, and adding the song ""Every Movie\'s a Circus"". This new production was better received by the critics and was an instant success, running for 369 performances. The Los Angeles production also recorded a new cast album that is well regarded. It is also the only unabridged cast recording of the show, since the original London recording was trimmed by over thirty minutes. A controversy arose with this production after Faye Dunaway was hired to replace Glenn Close. Dunaway went into rehearsals with Rex Smith as Joe and Jon Cypher as Max. Tickets "', 'Arthur Balfour | Balfour was appointed prime minister on 12 July 1902 while the King was recovering from his recent appendicitis operation. Changes to the Cabinet were thus not announced until 9 August, when the King was back in London. The new ministers were received in audience and took their oaths on 11 August.', 'Motel 6 | " Beginning in 1986, Motel 6 has advertised through radio commercials featuring the voice of writer and National Public Radio commentator Tom Bodett, with the tagline "We\'ll leave the light on for you." The ads were created by Dallas advertising agency The Richards Group. They feature a tune composed by Tom Faulkner, performed by him on guitar and Milo Deering on fiddle. The first spots were conceived and written by David Fowler. In 1996, the ads won a Clio Award. The campaign itself has won numerous national and international awards and was selected by Advertising Age magazine as one of the Top 100 Advertising Campaigns of the Twentieth Century."', ]
Motel 6 | " Beginning in 1986, Motel 6 has advertised through radio commercials featuring the voice of writer and National Public Radio commentator Tom Bodett, with the tagline "We'll leave the light on for you." The ads were created by Dallas advertising agency The Richards Group. They feature a tune composed by Tom Faulkner, performed by him on guitar and Milo Deering on fiddle. The first spots were conceived and written by David Fowler. In 1996, the ads won a Clio Award. The campaign itself has won numerous national and international awards and was selected by Advertising Age magazine as one of the Top 100 Advertising Campaigns of the Twentieth Century."
根据问题和检索到的文档构建新的 prompt:
1 2 3 4 5 6 7
rag_template = """[INST] Refer to the background document and answer the questions:
[INST] Refer to the background document and answer the questions:
Background: Motel 6 | " Beginning in 1986, Motel 6 has advertised through radio commercials featuring the voice of writer and National Public Radio commentator Tom Bodett, with the tagline "We'll leave the light on for you." The ads were created by Dallas advertising agency The Richards Group. They feature a tune composed by Tom Faulkner, performed by him on guitar and Milo Deering on fiddle. The first spots were conceived and written by David Fowler. In 1996, the ads won a Clio Award. The campaign itself has won numerous national and international awards and was selected by Advertising Age magazine as one of the Top 100 Advertising Campaigns of the Twentieth Century."
Question: What company advertised itself with the slogan "We'll leave a light on for you"? [/INST] The answer is:
[INST] Refer to the background document and answer the questions:
Background: <xRAG>
Question: What company advertised itself with the slogan "We'll leave a light on for you"? [/INST] The answer is:
Motel 6. The slogan was created in 1962 by Tom Bodett