参考教程:ollama-rag:60行代码实现一个基于Ollama的RAG系统
预备知识
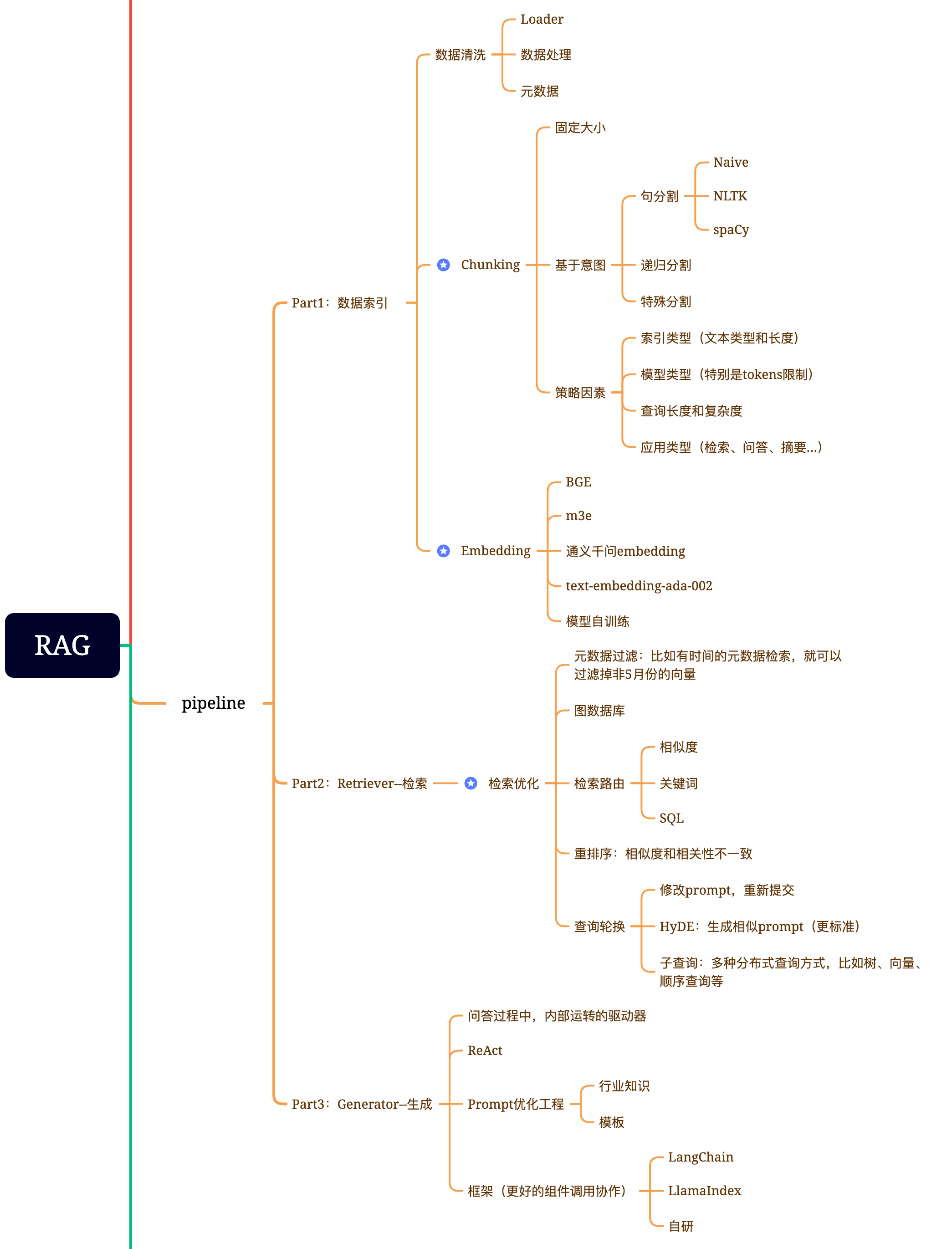
 RAG 应用技术原理
RAG 应用技术原理
 RAG 简单应用
RAG 简单应用
RAG 系统架构
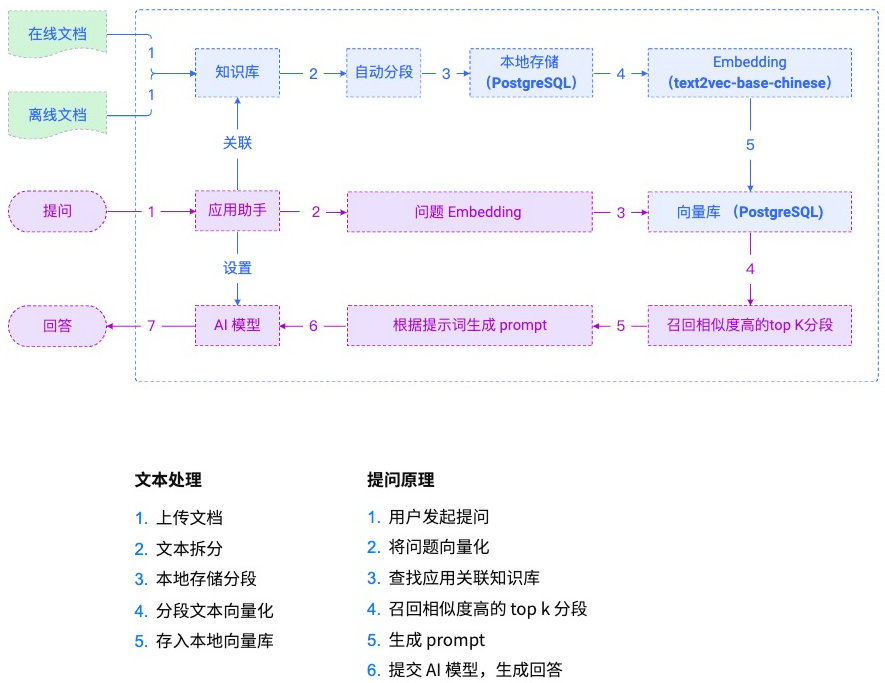
简化实现:
- Embedding 模型使用的是 Ollama 提供的文本转向量服务;
- 向量库使用的是 faiss 而不是 PostgreSQL;
- LLM 模型使用的也是 Ollama 提供的大模型服务。
Ollama 模型下载
1
2
| ollama pull nomic-embed-text:latest
ollama pull qwen:4b
|
环境配置
requirements.txt:
1
2
3
| ollama
faiss-cpu==1.8.0
tqdm
|
Anaconda Prompt:
1
2
3
| conda create -n rag Python==3.8
conda activate rag
pip install -r requirements.txt
|
代码实现
洗衣机常见错误编码及解决办法.txt:
E1 错误代码:E1 错误代码表示水位探测器故障。可能的原因包括水位开关、排水问题和其他电路问题。如果出现这种情况,建议关闭电源,检查洗衣机电路和水管,如有必要,清理管道和过滤器。如果问题依然存在,需要请专业维修人员进行维修。
E2 错误代码:E2 错误代码表示水阀故障。这可能是由于电路问题、水阀故障或水压过低造成的。解决方法是首先检查洗衣机水管是否有漏水问题,是否有别的水源可以上,同时检查电路和水阀。如果其他办法不能解决问题,最好请专业人员进行检修。
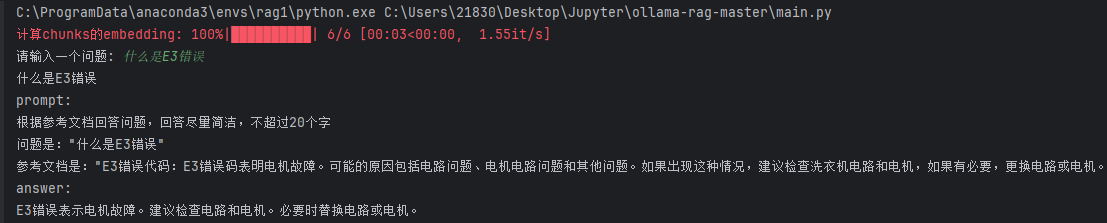
E3 错误代码:E3 错误码表明电机故障。可能的原因包括电路问题、电机电路问题和其他问题。如果出现这种情况,建议检查洗衣机电路和电机,如果有必要,更换电路或电机。
E4 错误代码:E4 错误代码表示放水泵问题。可能的原因包括电路故障、水泵故障或水箱堵塞。解决方法是清洗洗衣机水箱和过滤器,检查水泵和电路,并更换有问题的零件。
E5 错误代码:E5 错误代码表示电机过热故障。这可能是由于电路问题、风扇故障、电路板故障或其他问题引起的。解决方法是检查洗衣机电路和电机,检查散热器和风扇是否正常工作。如果有必要,更换故障零件。
E6 错误代码:E6 错误代码表示电路板故障。这可能是由于电源问题、电路板故障或其他问题引起的。解决方法是检查电源和电路板,如有必要,更换故障零件。
main.py:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| import faiss
import ollama
from tqdm import tqdm
import numpy as np
def encode(text):
return ollama.embeddings(model = 'nomic-embed-text', prompt = text)['embedding']
chunks = []
file = open("洗衣机常见错误编码及解决办法.txt", encoding = 'utf-8')
for line in file:
line = line.strip()
if line:
chunks.append(line)
file.close()
chunk_embeddings = []
for i in tqdm(range(len(chunks)), desc = '计算chunks的embedding'):
chunk_embeddings.append(encode(chunks[i]))
chunk_embeddings = np.array(chunk_embeddings)
chunk_embeddings = chunk_embeddings.astype('float32')
faiss.normalize_L2(chunk_embeddings)
faiss_index = faiss.index_factory(chunk_embeddings.shape[1], "Flat", faiss.METRIC_INNER_PRODUCT)
faiss_index.add(chunk_embeddings)
while True:
question = input("请输入一个问题: ")
print(question)
question_embedding = encode(question)
question_embedding = np.array([question_embedding])
question_embedding = question_embedding.astype('float32')
faiss.normalize_L2(question_embedding)
_, index_matrix = faiss_index.search(question_embedding, k = 1)
prompt = f'根据参考文档回答问题,回答尽量简洁,不超过20个字\n' \
f'问题是:"{question}"\n' \
f'参考文档是:"{chunks[index_matrix[0][0]]}"'
print(f'prompt:\n{prompt}')
stream = ollama.chat(model = 'qwen:4b', messages = [{'role': 'user', 'content': prompt}], stream = True)
print('answer:')
for chunk in stream:
print(chunk['message']['content'], end = '', flush = True)
print()
|
报错:
- 缺少“packaging”:在 rag 环境下安装
pip install packaging
- 读取 txt 时 gbk 错误:open 函数添加
encoding = 'utf-8'