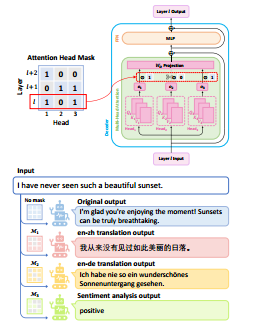
方法图示:
参考项目:OpenDFM/HeadsUp
1 安装 1.1 虚拟环境 1 2 3 4 5 6 7 8 9 conda create -n heads python=3.10 -y
1.2 项目结构 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 dataset/ / / / / 15 way/ 15 way.orig.tsv/ / / / / / / / / /
1.3 模型和 Mask 矩阵 模型:
1 2 huggingface-cli download --token Your_token meta-llama/Meta-Llama-3.1-8B-Instruct --local-dir model/Llama-3.1-8B-Instruct
Mask 矩阵 :下载 fv/adjective_v_verb_3/ 和 fv/verb_v_adjective_3/。
2 整体流程 2.1 训练 Mask 矩阵
导入必要的库:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import argparseimport copyimport osimport refrom dataclasses import dataclass, fieldfrom tqdm import tqdmimport torchfrom torch import nnimport safetensors.torchimport itertoolsimport numpy as npimport pandas as pdimport datasetsfrom datasets import Dataset, concatenate_datasetsfrom models.modeling_llama import LlamaForCausalLMfrom models.modeling_phi3 import Phi3ForCausalLMfrom models.modeling_mistral import MistralForCausalLMfrom models.modeling_qwen2 import Qwen2ForCausalLMfrom models.modeling_gemma2 import Gemma2ForCausalLMfrom transformers import AutoTokenizer, DataCollatorForLanguageModeling, Trainer, TrainingArguments, HfArgumentParserfrom rouge_score import rouge_scorerfrom nltk.translate.bleu_score import sentence_bleu, SmoothingFunctionimport jiebaimport matplotlib.pyplot as pltimport matplotlib as mplimport seaborn as snsfrom adjustText import adjust_text
重新定义训练器:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 class SimpleTensorModel (nn.Module):def __init__ (self, tensor_length=1056 ):super ().__init__()self .tensor = nn.Parameter(torch.zeros(tensor_length)) self .tensor, mean=4 , std=0.02 ) def forward (self, x=None ):return self .tensorclass CustomDataCollator (DataCollatorForLanguageModeling ):def __init__ (self, lm_tokenizer, padding=True ):self .lm_tokenizer = lm_tokenizerself .padding = paddingdef torch_call (self, features ):"lm_input_ids" ] for f in features]"lm_labels" ]) for f in features]self .lm_tokenizer.pad({"input_ids" : lm_input_ids}, padding=self .padding, return_tensors="pt" )True , padding_value=-100 )return {"lm_input_ids" : lm_batch["input_ids" ], "lm_attention_mask" : lm_batch["attention_mask" ], "lm_labels" : lm_labels}def gumbel_sigmoid (logits, tau=1 , hard=False , threshold=0.5 ):if hard:True ) 0 ], indices[1 ]] = 1.0 else :return retclass CustomTrainer (Trainer ):def __init__ (self, *args, lm_model, lm_tokenizer, **kwargs ):super ().__init__(*args, **kwargs)self .lm_model = lm_modelself .lm_tokenizer = lm_tokenizerdef compute_loss (self, model, inputs, return_outputs=False , num_items_in_batch=None ):"lm_input_ids" ].to(self .args.device)"lm_attention_mask" ].to(self .args.device)"lm_labels" ].to(self .args.device)0 ) None ).unsqueeze(0 ).repeat(bsz, 1 )if self .args.tau_decay_steps < 1 : int (self .args.tau_decay_steps * self .state.max_steps)else :int (self .args.tau_decay_steps)if self .state.global_step >= tau_decay_end_step:self .args.tau_temp_endelse :self .state.global_step / tau_decay_end_stepself .args.tau_temp_begin - decay_ratio * (self .args.tau_temp_begin - self .args.tau_temp_end)if self .args.use_gumbel:self .args.gumbel_hard)else :self .lm_model.device)self .lm_model(lm_input_ids, attention_mask=lm_attention_mask, weight_tensor=weights_tensor, labels=lm_labels, use_cache=False )self .args.norm_lambdasum (weights_tensor, dim=1 ).mean()self .log({"pred_output_loss" : pred_output_loss.item(), "normalizer" : normalizer.item(), "tau_temp" : tau_temp, "total_loss" : loss.item()})return (loss, pred_outputs) if return_outputs else lossdef prediction_step (self, model, inputs, prediction_loss_only, ignore_keys=None ):"lm_input_ids" ].to(self .args.device)"lm_labels" ].to(self .args.device)0 )with torch.no_grad():None ).unsqueeze(0 ).repeat(bsz, 1 ) 0.5 ).to(weights_logit.dtype) self .lm_model.device)None for one_lm_input_ids, one_lm_labels, one_weights_tensor in zip (lm_input_ids, lm_labels, weights_tensor):100 ].unsqueeze(0 )self .lm_model.generate(one_lm_scr_input_ids, attention_mask=one_lm_attention_mask, max_new_tokens=30 , weight_tensor=one_weights_tensor.unsqueeze(0 ), do_sample=False )self .lm_tokenizer.decode(generate_ids[0 ], skip_special_tokens=True )print ("[GENERATED]" , pred_str)if prediction_loss_only:return (pred_output_loss, None , None )None return (pred_output_loss, lm_logits, lm_labels)
定义模板字符串和预处理函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 "<|begin_of_text|><|start_header_id|>user<|end_header_id|>\n\n{src}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n" "<|begin_of_text|>{src}\n\n" "<|user|>\n{src}<|end|>\n<|assistant|>\n" "<s>[INST] {src}[/INST]" "<|im_start|>user\n{src}<|im_end|>\n<|im_start|>assistant\n" "{src}\n\n" "<bos><start_of_turn>user\n{src}<end_of_turn>\n<start_of_turn>model\n" def preprocess_batch (samples, lm_tokenizer, model_type, fewshot_dataset=None ):assert model_type in ["llama" , "llama-plm" , "phi3" , "mistral" , "qwen2" , "qwen2-plm" , "gemma2" ] "" if model_type == "llama" :format (src=input_str.strip()) + f"{target_str.strip()} <|eot_id|>" for input_str, target_str in zip (samples["input_str" ], samples["target_str" ])]elif model_type == "llama-plm" :format (src=input_str.strip()) + f"{target_str.strip()} <|end_of_text|>" for input_str, target_str in zip (samples["input_str" ], samples["target_str" ])]elif model_type == "phi3" :format (src=input_str.strip()) + f"{target_str.strip()} <|end|>" for input_str, target_str in zip (samples["input_str" ], samples["target_str" ])]elif model_type == "mistral" :format (src=input_str.strip()) + f" {target_str.strip()} </s>" for input_str, target_str in zip (samples["input_str" ], samples["target_str" ])]elif model_type == "qwen2" :format (src=input_str.strip()) + f"{target_str.strip()} <|im_end|>" for input_str, target_str in zip (samples["input_str" ], samples["target_str" ])]elif model_type == "qwen2-plm" :format (src=input_str.strip()) + f"{target_str.strip()} <|endoftext|>" for input_str, target_str in zip (samples["input_str" ], samples["target_str" ])]elif model_type == "gemma2" :format (src=input_str.strip()) + f"{target_str.strip()} <end_of_turn>" for input_str, target_str in zip (samples["input_str" ], samples["target_str" ])]32768 , truncation=True , padding=False , add_special_tokens=False ,return_tensors="np" )len (lm_tokenizer(template.format (src=input_str.strip()), add_special_tokens=False )["input_ids" ]) for input_str in samples["input_str" ]] "input_ids" ])for i, input_str_len in enumerate (input_str_lens):100 return {"lm_input_ids" : lm_inputs["input_ids" ], "lm_labels" : labels}def preprocess_fewshot_batch (samples, lm_tokenizer, model_type, fewshot_dataset ):assert model_type in ["llama" ] "<|begin_of_text|>" for sample in fewshot_dataset:"input_str" ], sample["target_str" ]f"<|start_header_id|>user<|end_header_id|>\n\n{input_str.strip()} <|eot_id|>" f"<|start_header_id|>assistant<|end_header_id|>\n\n{target_str.strip()} <|eot_id|>" "<|start_header_id|>user<|end_header_id|>\n\n{src}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n" format (src=input_str.strip()) + f"{target_str.strip()} <|eot_id|>" for input_str, target_str in zip (samples["input_str" ], samples["target_str" ])]32768 , truncation=True , padding=False , add_special_tokens=False ,return_tensors="np" )len (lm_tokenizer(template.format (src=input_str.strip()), add_special_tokens=False )["input_ids" ]) for input_str in samples["input_str" ]]"input_ids" ])for i, input_str_len in enumerate (input_str_lens):100 return {"lm_input_ids" : lm_inputs["input_ids" ], "lm_labels" : labels}
定义训练过程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 def search_weight_embed (lm_model, task, args, training_args ):True )f"{model_name} -train_weight-{task} " True )"right" "right" "cuda" )) if not args.dataset_use_cache:None , None None if "XNLI" in args.train_data_path:"_" )"ar" : "Arabic" , "fr" : "French" , "es" : "Spanish" , "de" : "German" , "en" : "English" , "ru" : "Russian" , "zh" : "Chinese" }def _preprocess_xnli (dataset ):for src_lang, tgt_lang in itertools.combinations(LANG_LIST, 2 ):map (lambda sample: {"input_str" : f"{sample[src_lang]} " , "target_str" : sample[tgt_lang]}).select_columns(["input_str" , "target_str" ])return concatenate_datasets(pair_datasets)'\t' ).select_columns(LANG_LIST)range (len (dataset) - 100 ))range (len (dataset) - 100 , len (dataset)))elif "function_vectors" in args.train_data_path:if "fewshot" in args.train_data_path:map (lambda sample: {"input_str" : sample["input" ], "target_str" : sample["output" ]})"input" , "output" ])range (min (len (dataset) - 100 , 10000 ))).shuffle(seed=args.seed)range (5 )), dataset.select(range (5 , len (dataset)))else :map (lambda sample: {"input_str" : str (sample["input" ]), "target_str" : str (sample["output" ])})"input" , "output" ])range (min (len (dataset) - 100 , 10000 )))range (len (dataset) - 100 , len (dataset)))else :assert False , "Unsupported dataset" map (lambda sample: map_func(sample, lm_tokenizer, model_type=args.model_type, fewshot_dataset=fewshot_dataset),True ,128 ,1 ,".cache/train_dataset_cache.arrow" ) if args.dataset_use_cache else None filter (lambda sample: len (sample["lm_input_ids" ]) <= args.max_seq_length,False map (lambda sample: map_func(sample, lm_tokenizer, model_type=args.model_type, fewshot_dataset=fewshot_dataset),True ,128 ,1 ,".cache/dev_dataset_cache.arrow" ) if args.dataset_use_cache else None filter (lambda sample: len (sample["lm_input_ids" ]) <= args.max_seq_length,False True )None ,False )
定义相关参数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 @dataclass class ModelArguments :str = field(default="../model/bge-reranker-v2-m3" , metadata={"help" : "嵌入模型路径" })str = field(default="../model/Llama-3.1-8B-Instruct" , metadata={"help" : "语言模型路径" })str = field(default="llama" , metadata={"help" : "模型类型(plm 表示纯语言模型)" })@dataclass class DataArguments :str = field(default="dataset/XNLI-15way/xnli.15way.orig.tsv" , metadata={"help" : "训练数据路径" })str = field(default="dataset/XNLI-15way/xnli.15way.orig.tsv" , metadata={"help" : "验证数据路径" })bool = field(default=False , metadata={"help" : "是否使用数据集缓存" })int = field(default=32768 , metadata={"help" : "输入的最大序列长度" })@dataclass class CustomTrainingArguments (TrainingArguments ):float = field(default=4.0 , metadata={"help" : "Gumbel-Sigmoid 的初始温度" })float = field(default=0.05 , metadata={"help" : "Gumbel-Sigmoid 的最终温度" })float = field(default=0.4 , metadata={"help" : "Gumbel-Sigmoid 温度的衰减步数(若小于 1,则表示占总训练步数的比例)" })float = field(default=0 , metadata={"help" : "权重张量归一化的 lambda 系数" })float = field(default=1 , metadata={"help" : "权重张量归一化的幂次" })bool = field(default=True , metadata={"help" : "是否对权重张量使用 Gumbel-Sigmoid" })bool = field(default=True , metadata={"help" : "是否使用 hard 形式的 Gumbel-Sigmoid" })True )False "output/llama/xnli" True 10 4 1 False 31 200 True "logs" 500 1e-2 "cosine_with_min_lr" "min_lr" : 1e-4 } True 0.1 4 vars (model_args), **vars (training_args), **vars (data_args))print (args)
Namespace(embed_model_path='../model/bge-reranker-v2-m3', lm_model_path='../model/Llama-3.1-8B-Instruct', model_type='llama', output_dir='output/llama/xnli', overwrite_output_dir=True, do_train=False, do_eval=False, do_predict=False, eval_strategy=<IntervalStrategy.NO: 'no'>, prediction_loss_only=False, per_device_train_batch_size=4, per_device_eval_batch_size=1, per_gpu_train_batch_size=None, per_gpu_eval_batch_size=None, gradient_accumulation_steps=4, eval_accumulation_steps=None, eval_delay=0, torch_empty_cache_steps=None, learning_rate=0.01, weight_decay=0.0, adam_beta1=0.9, adam_beta2=0.999, adam_epsilon=1e-08, max_grad_norm=1.0, num_train_epochs=10, max_steps=-1, lr_scheduler_type='cosine_with_min_lr', lr_scheduler_kwargs={'min_lr': 0.0001}, warmup_ratio=0.1, warmup_steps=0, log_level='passive', log_level_replica='warning', log_on_each_node=True, logging_dir='logs', logging_strategy=<IntervalStrategy.STEPS: 'steps'>, logging_first_step=False, logging_steps=500, logging_nan_inf_filter=True, save_strategy=<SaveStrategy.STEPS: 'steps'>, save_steps=31, save_total_limit=200, save_safetensors=True, save_on_each_node=False, save_only_model=True, restore_callback_states_from_checkpoint=False, no_cuda=False, use_cpu=False, use_mps_device=False, seed=42, data_seed=None, jit_mode_eval=False, use_ipex=False, bf16=True, fp16=False, fp16_opt_level='O1', half_precision_backend='auto', bf16_full_eval=False, fp16_full_eval=False, tf32=None, local_rank=0, ddp_backend=None, tpu_num_cores=None, tpu_metrics_debug=False, debug=[], dataloader_drop_last=False, eval_steps=None, dataloader_num_workers=0, dataloader_prefetch_factor=None, past_index=-1, run_name='trainer_output', disable_tqdm=False, remove_unused_columns=False, label_names=None, load_best_model_at_end=False, metric_for_best_model=None, greater_is_better=None, ignore_data_skip=False, fsdp=[], fsdp_min_num_params=0, fsdp_config={'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}, tp_size=0, fsdp_transformer_layer_cls_to_wrap=None, accelerator_config=AcceleratorConfig(split_batches=False, dispatch_batches=None, even_batches=True, use_seedable_sampler=True, non_blocking=False, gradient_accumulation_kwargs=None, use_configured_state=False), deepspeed=None, label_smoothing_factor=0.0, optim=<OptimizerNames.ADAMW_TORCH: 'adamw_torch'>, optim_args=None, adafactor=False, group_by_length=False, length_column_name='length', report_to=[], ddp_find_unused_parameters=None, ddp_bucket_cap_mb=None, ddp_broadcast_buffers=None, dataloader_pin_memory=True, dataloader_persistent_workers=False, skip_memory_metrics=True, use_legacy_prediction_loop=False, push_to_hub=False, resume_from_checkpoint=None, hub_model_id=None, hub_strategy=<HubStrategy.EVERY_SAVE: 'every_save'>, hub_token=None, hub_private_repo=None, hub_always_push=False, gradient_checkpointing=False, gradient_checkpointing_kwargs=None, include_inputs_for_metrics=False, include_for_metrics=[], eval_do_concat_batches=True, fp16_backend='auto', push_to_hub_model_id=None, push_to_hub_organization=None, push_to_hub_token=None, mp_parameters='', auto_find_batch_size=False, full_determinism=False, torchdynamo=None, ray_scope='last', ddp_timeout=1800, torch_compile=False, torch_compile_backend=None, torch_compile_mode=None, include_tokens_per_second=False, include_num_input_tokens_seen=False, neftune_noise_alpha=None, optim_target_modules=None, batch_eval_metrics=False, eval_on_start=False, use_liger_kernel=False, eval_use_gather_object=False, average_tokens_across_devices=False, tau_temp_begin=4.0, tau_temp_end=0.05, tau_decay_steps=0.4, norm_lambda=0, norm_power=1, use_gumbel=True, gumbel_hard=True, distributed_state=Distributed environment: NO
Num processes: 1
Process index: 0
Local process index: 0
Device: cuda
, _n_gpu=1, __cached__setup_devices=device(type='cuda', index=0), deepspeed_plugin=None, train_data_path='dataset/XNLI-15way/xnli.15way.orig.tsv', dev_data_path='dataset/XNLI-15way/xnli.15way.orig.tsv', dataset_use_cache=False, max_seq_length=32768)
选择模型类:
1 2 3 4 5 6 7 8 9 10 11 12 13 if "phi3" in args.model_type:elif "llama" in args.model_type:elif "mistral" in args.model_type:elif "qwen2" in args.model_type:elif "gemma2" in args.model_type:else :assert False , "Unsupported model type" print (f"Using model type: {casual_lm.__name__} " )
Using model type: LlamaForCausalLM
加载语言模型:
1 2 3 4 5 6 7 8 lm_model = casual_lm.from_pretrained(True , f"cuda:{int (os.environ['LOCAL_RANK' ])} " ) if args.distributed_state.use_distributed else "auto" , "flash_attention_2" ,32768
Loading checkpoint shards: 100%|██████████| 4/4 [00:21<00:00, 5.39s/it]
机器翻译训练,以中英翻译为例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 train_data_dir = args.train_data_pathif "XNLI" in train_data_dir:"en" , "zh" ]for i, (src_lang, tgt_lang) in enumerate (itertools.permutations(ALL_LANGS, 2 )):print (f"\n********** [{i+1 } /{len (ALL_LANGS) * (len (ALL_LANGS) - 1 )} ] Training {src_lang} -> {tgt_lang} **********\n" )f"{src_lang} _{tgt_lang} " , args, training_args)elif "function_vectors" in train_data_dir:for root, dirs, files in os.walk(train_data_dir):for file in files:if file.endswith(".json" ):"." )[0 ]print (f"\n********** Training {task} **********\n" )else :assert False , "Unsupported dataset"
********** [1/2] Training en -> zh **********
Map: 100%|██████████| 9900/9900 [00:00<00:00, 24753.96 examples/s]
Map: 100%|██████████| 100/100 [00:00<00:00, 16005.74 examples/s]
Map: 100%|██████████| 9900/9900 [00:01<00:00, 7272.35 examples/s]
Filter: 100%|██████████| 9900/9900 [00:00<00:00, 31385.21 examples/s]
Map: 100%|██████████| 100/100 [00:00<00:00, 5276.52 examples/s]
Filter: 100%|██████████| 100/100 [00:00<00:00, 18811.07 examples/s]
Step Training Loss
500 2.330100
1000 1.664200
1500 1.343300
2000 1.235700
2500 1.195600
3000 1.178300
3500 1.163300
4000 1.172700
4500 1.192800
5000 1.158600
5500 1.169000
6000 1.143300
********** [2/2] Training zh -> en **********
Map: 100%|██████████| 9900/9900 [00:00<00:00, 32588.55 examples/s]
Map: 100%|██████████| 100/100 [00:00<00:00, 17755.17 examples/s]
Map: 100%|██████████| 9900/9900 [00:01<00:00, 6584.71 examples/s]
Filter: 100%|██████████| 9900/9900 [00:00<00:00, 29741.66 examples/s]
Map: 100%|██████████| 100/100 [00:00<00:00, 5468.88 examples/s]
Filter: 100%|██████████| 100/100 [00:00<00:00, 17750.66 examples/s]
Step Training Loss
500 1.758600
1000 1.261800
1500 1.209500
2000 1.180300
2500 1.206600
3000 1.192100
3500 1.170300
4000 1.188600
4500 1.199100
5000 1.178500
5500 1.170500
6000 1.145500
替换为任务的参数:
1 2 3 4 5 6 7 8 9 10 data_args.train_data_path = "dataset/function_vectors/abstractive" "dataset/function_vectors/abstractive" "output/llama/fv" 3 6250 625 vars (model_args), **vars (training_args), **vars (data_args))print (args)
Namespace(embed_model_path='../model/bge-reranker-v2-m3', lm_model_path='../model/Llama-3.1-8B-Instruct', model_type='llama', output_dir='output/llama/fv', overwrite_output_dir=True, do_train=False, do_eval=False, do_predict=False, eval_strategy=<IntervalStrategy.NO: 'no'>, prediction_loss_only=False, per_device_train_batch_size=4, per_device_eval_batch_size=1, per_gpu_train_batch_size=None, per_gpu_eval_batch_size=None, gradient_accumulation_steps=4, eval_accumulation_steps=None, eval_delay=0, torch_empty_cache_steps=None, learning_rate=0.01, weight_decay=0.0, adam_beta1=0.9, adam_beta2=0.999, adam_epsilon=1e-08, max_grad_norm=1.0, num_train_epochs=3, max_steps=6250, lr_scheduler_type='cosine_with_min_lr', lr_scheduler_kwargs={'min_lr': 0.0001}, warmup_ratio=0.1, warmup_steps=0, log_level='passive', log_level_replica='warning', log_on_each_node=True, logging_dir='logs', logging_strategy=<IntervalStrategy.STEPS: 'steps'>, logging_first_step=False, logging_steps=500, logging_nan_inf_filter=True, save_strategy=<SaveStrategy.STEPS: 'steps'>, save_steps=31, save_total_limit=200, save_safetensors=True, save_on_each_node=False, save_only_model=True, restore_callback_states_from_checkpoint=False, no_cuda=False, use_cpu=False, use_mps_device=False, seed=42, data_seed=None, jit_mode_eval=False, use_ipex=False, bf16=True, fp16=False, fp16_opt_level='O1', half_precision_backend='auto', bf16_full_eval=False, fp16_full_eval=False, tf32=None, local_rank=0, ddp_backend=None, tpu_num_cores=None, tpu_metrics_debug=False, debug=[], dataloader_drop_last=False, eval_steps=625, dataloader_num_workers=0, dataloader_prefetch_factor=None, past_index=-1, run_name='trainer_output', disable_tqdm=False, remove_unused_columns=False, label_names=None, load_best_model_at_end=False, metric_for_best_model=None, greater_is_better=None, ignore_data_skip=False, fsdp=[], fsdp_min_num_params=0, fsdp_config={'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}, tp_size=0, fsdp_transformer_layer_cls_to_wrap=None, accelerator_config=AcceleratorConfig(split_batches=False, dispatch_batches=None, even_batches=True, use_seedable_sampler=True, non_blocking=False, gradient_accumulation_kwargs=None, use_configured_state=False), deepspeed=None, label_smoothing_factor=0.0, optim=<OptimizerNames.ADAMW_TORCH: 'adamw_torch'>, optim_args=None, adafactor=False, group_by_length=False, length_column_name='length', report_to=[], ddp_find_unused_parameters=None, ddp_bucket_cap_mb=None, ddp_broadcast_buffers=None, dataloader_pin_memory=True, dataloader_persistent_workers=False, skip_memory_metrics=True, use_legacy_prediction_loop=False, push_to_hub=False, resume_from_checkpoint=None, hub_model_id=None, hub_strategy=<HubStrategy.EVERY_SAVE: 'every_save'>, hub_token=None, hub_private_repo=None, hub_always_push=False, gradient_checkpointing=False, gradient_checkpointing_kwargs=None, include_inputs_for_metrics=False, include_for_metrics=[], eval_do_concat_batches=True, fp16_backend='auto', push_to_hub_model_id=None, push_to_hub_organization=None, push_to_hub_token=None, mp_parameters='', auto_find_batch_size=False, full_determinism=False, torchdynamo=None, ray_scope='last', ddp_timeout=1800, torch_compile=False, torch_compile_backend=None, torch_compile_mode=None, include_tokens_per_second=False, include_num_input_tokens_seen=False, neftune_noise_alpha=None, optim_target_modules=None, batch_eval_metrics=False, eval_on_start=False, use_liger_kernel=False, eval_use_gather_object=False, average_tokens_across_devices=False, tau_temp_begin=4.0, tau_temp_end=0.05, tau_decay_steps=0.4, norm_lambda=0, norm_power=1, use_gumbel=True, gumbel_hard=True, distributed_state=Distributed environment: NO
Num processes: 1
Process index: 0
Local process index: 0
Device: cuda
, _n_gpu=1, __cached__setup_devices=device(type='cuda', index=0), deepspeed_plugin=None, train_data_path='dataset/function_vectors/abstractive', dev_data_path='dataset/function_vectors/abstractive', dataset_use_cache=False, max_seq_length=32768)
任务训练,以反义词任务为例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 train_data_dir = args.train_data_pathif "XNLI" in train_data_dir:"en" , "zh" , "fr" , "de" , "es" , "ru" , "ar" ]for i, (src_lang, tgt_lang) in enumerate (itertools.permutations(ALL_LANGS, 2 )):print (f"\n********** [{i+1 } /{len (ALL_LANGS) * (len (ALL_LANGS) - 1 )} ] Training {src_lang} -> {tgt_lang} **********\n" )f"{src_lang} _{tgt_lang} " , args, training_args)elif "function_vectors" in train_data_dir:for root, dirs, files in os.walk(train_data_dir):for file in files:if file.endswith("antonym.json" ): "." )[0 ]print (f"\n********** Training {task} **********\n" )else :assert False , "Unsupported dataset"
********** Training antonym **********
Generating train split: 2398 examples [00:00, 77072.94 examples/s]
Map: 100%|██████████| 2398/2398 [00:00<00:00, 36112.36 examples/s]
Map: 100%|██████████| 2298/2298 [00:00<00:00, 7820.68 examples/s]
Filter: 100%|██████████| 2298/2298 [00:00<00:00, 59810.06 examples/s]
Map: 100%|██████████| 100/100 [00:00<00:00, 3802.15 examples/s]
Filter: 100%|██████████| 100/100 [00:00<00:00, 12812.90 examples/s]
Step Training Loss
500 6.312800
1000 1.012000
1500 0.716200
2000 0.607200
2500 0.609400
3000 0.585000
3500 0.594200
4000 0.583300
4500 0.586900
5000 0.554000
5500 0.540600
6000 0.546000
训练结束后,保存路径下会有若干个 checkpoint- 开头的文件夹,每个文件夹里面的内容为:
1 2 3 model.safetensors json bin
2.2 评估
读取训练的不同任务的注意力头 Mask 权重:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 weight_dict = {}for root, dir , files in os.walk("output/llama/xnli" ):for file in files:if file.endswith(".safetensors" ) and "-6180" in root:"tensor" ] for root, dir , files in os.walk("output/llama/fv" ):for file in files:if file.endswith(".safetensors" ) and "-6250" in root:"tensor" ]print ("Total tasks:" , len (weight_dict))print ("Task name" , "\t" , "Weight" , "\t" , "# of up heads" )for k, v in sorted (weight_dict.items()):print (k, "\t" , v, "\t" , (v.sigmoid() >= 0.5 ).sum ().item())
Total tasks: 5
Task name Weight # of up heads
adjective_v_verb_3 tensor([6.4547, 0.8442, 4.9701, ..., 6.9430, 5.0350, 3.9923]) 845
antonym tensor([4.9961, 4.3987, 4.5589, ..., 7.8902, 3.0385, 3.9649]) 864
en_zh tensor([5.2550, 1.9984, 5.9432, ..., 7.5652, 3.0530, 4.0198]) 856
verb_v_adjective_3 tensor([6.7996, 2.7995, 6.5897, ..., 7.7574, 5.2005, 3.9966]) 871
zh_en tensor([ 1.6995, 3.6389, 6.9171, ..., 4.2308, -1.9574, 3.9649]) 966
载入模型和分词器,选择模板:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 DEVICE = "cuda:0" "../model/Llama-3.1-8B-Instruct" True )True , device_map=DEVICE, torch_dtype=torch.bfloat16, attn_implementation="eager" , max_position_embeddings=2048 )if "llama" in model_name:if "instruct" in model_name:print ("using LLAMA_TEMPLATE" )else :print ("using LLAMA_PLM_TEMPLATE" )elif "qwen2" in model_name:if "instruct" in model_name:print ("using QWEN2_TEMPLATE" )else :print ("using QWEN2_PLM_TEMPLATE" )else :print ("Unknown model" )
Loading checkpoint shards: 100%|██████████| 4/4 [00:19<00:00, 4.79s/it]
using LLAMA_TEMPLATE
任务提示词:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 TASK_DICT = {"lowercase_first_letter" : "Output the first letter of the given word in lowercase." ,"park-country" : "Identify the country where the given national park is located." ,"synonym" : "Identify a synonym for the given word." ,"ag_news" : "Classify the given news headline into one of the categories: Business, Science, Sports, or World. Provide only the category name." ,"word_length" : "Determine the number of letters in the given word and output the count." ,"present-past" : "Convert the given verb from its present tense to its simple past tense." ,"capitalize" : "Output the given word with its first letter capitalized." ,"landmark-country" : "Identify the country where the given landmark is located." ,"english-german" : "Translate the given English word into German." ,"sentiment" : "Determine the sentiment of the given input. Output either 'positive' or 'negative'." ,"country-capital" : "What is the capital of the given country? Provide only the name of the capital." ,"person-occupation" : "Identify the occupation of the given individual." ,"country-currency" : "What is the official currency of the given country?" ,"lowercase_last_letter" : "Output the last letter of the given word in lowercase." ,"person-sport" : "Identify the sport associated with the given individual." ,"person-instrument" : "Identify the musical instrument played by the given musician." ,"antonym" : "Identify the antonym of the given word." ,"capitalize_last_letter" : "Output the last letter of the given word in uppercase." ,"english-french" : "Translate the given English word into French." ,"next_item" : "What is the next sequential item following the given input?" ,"singular-plural" : "Provide the plural form of the given singular noun." ,"capitalize_second_letter" : "Output the second letter of the given word in uppercase." ,"prev_item" : "What is the item that comes before the given input in a sequential context?" ,"capitalize_first_letter" : "Output the first letter of the given word in uppercase." ,"english-spanish" : "Translate the given English word into Spanish." ,"next_capital_letter" : "What is the next uppercase letter in alphabetical order after the given input?" ,"national_parks" : "Identify the U.S. state where the given national park is located." ,"product-company" : "Identify the company associated with the given product." ,"conll2003_organization" : "Extract the organization mentioned in the given text." ,"conll2003_person" : "Extract the name of the person mentioned in the given text." ,"conll2003_location" : "Extract the location mentioned in the given text." ,"adjective_v_verb_3" : "From the given words, identify the one that is an adjective." ,"object_v_concept_3" : "From the given words, identify the one that is a object." ,"verb_v_adjective_3" : "From the given words, identify the one that is a verb." ,"fruit_v_animal_3" : "From the given words, identify the one that is a fruit."
评估反义词任务:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 def eval_function_vectors (use_instruction, use_mask ):for root, dirs, files in os.walk("dataset/function_vectors/abstractive" ):for file in files:if file.endswith("antonym.json" ):"." )[0 ] map (lambda sample: {"input_str" : TASK_DICT[task] + f"\n\nInput:\n\n{sample['input' ]} \n\nOutput:\n\n" if use_instruction else sample["input" ],"target_str" : sample["output" ]"input" , "output" ]) range (len (dataset) - 100 , len (dataset))) for task, dataset in tqdm(dev_datasets):0.5 ).float ().numpy() 0 ).repeat(1 , 1 ).to(model.device) 0 for sample in dataset:str (sample["input_str" ]), str (sample["target_str" ])format (src=input_str.strip()) 2048 , truncation=True , padding=False , add_special_tokens=False ,return_tensors="pt" ).to(DEVICE)with torch.no_grad():if use_mask:10 , weight_tensor=mask_tensor, do_sample=False )else :10 , weight_tensor=None , do_sample=False )0 ][lm_inputs_src.input_ids.size(1 ):], skip_special_tokens=True ) if task in ["capitalize_first_letter" , "capitalize_last_letter" , "capitalize_second_letter" , "capitalize" , "lowercase_first_letter" , "lowercase_last_letter" , "next_capital_letter" , "next_item" , "prev_item" , "commonsense_qa" ,"conll2003_organization" , "conll2003_person" , "conll2003_location" , "adjective_v_verb_3" , "object_v_concept_3" , "verb_v_adjective_3" , "fruit_v_animal_3" ,if pred_str.strip().startswith(target_str.strip()): 1 else : if target_str.strip() in pred_str.strip():1 len (dataset)print (f"{task} : {score} " )print ("使用指令,使用Mask" )True , use_mask=True )print ("使用指令,不使用Mask" )True , use_mask=False )print ("不使用指令,使用Mask" )False , use_mask=True )print ("不使用指令,不使用Mask" )False , use_mask=False )
using LLAMA_TEMPLATE
使用指令,使用Mask
100%|██████████| 1/1 [00:10<00:00, 10.85s/it]
antonym: 0.63
使用指令,不使用Mask
100%|██████████| 1/1 [00:30<00:00, 30.66s/it]
antonym: 0.3
不使用指令,使用Mask
100%|██████████| 1/1 [00:08<00:00, 8.78s/it]
antonym: 0.76
不使用指令,不使用Mask
100%|██████████| 1/1 [00:30<00:00, 30.58s/it]
antonym: 0.12
观察对比抽取任务的注意力分布情况:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 dev_datasets = []for root, dirs, files in os.walk("dataset/function_vectors/abstractive" ):for file in files:if file.endswith("verb_3.json" ) or file.endswith("adjective_3.json" ):"." )[0 ]if "_v_" not in task: continue map (lambda sample: {"input_str" : sample["input" ], "target_str" : sample["output" ]})"input" , "output" ])range (len (dataset) - 100 , len (dataset)))def find_segments_ (l ):for i, x in enumerate (l) if x == 271 ] 0 ], indices_271[1 ] 1 :end] for idx, value in enumerate (segment, start=start + 1 ):if value == 11 :if current_segment:else :if current_segment:return segmentsfor task, dataset in tqdm(dev_datasets):0.5 ).float ().numpy()0 ).repeat(1 , 1 ).to(model.device)"_v_" )[0 ], task.split("_v_" )[1 ][:-2 ] for sample in dataset:"input_str" ].split(", " ).index(sample["target_str" ]) f"{sample['input_str' ]} \n\nChoose the {choose_the} out of {choose_from} s:" f"{sample['input_str' ]} " format (src=input_inst_str)], add_special_tokens=False , return_tensors="pt" ).to(DEVICE) 0 ].tolist()) assert len (lm_inputs_inst_src_choice_idx) == 3 format (src=input_str)], add_special_tokens=False , return_tensors="pt" ).to(DEVICE) with torch.no_grad():None , output_attentions=True )1 , :, -1 ] 0 ,1 )).float ().cpu().numpy() sum () for i in range (3 )] sum (original_choice_attentions) True )1 , :, -1 ]32 ,33 )[:, :-1 ] == 0 ] = 0 32 ,33 )[:, :-1 ] != 0 ).sum (dim=1 ) sum (dim=(0 ,1 )) / (mask_tensor.sum () - 32 )).float ().cpu().numpy()sum () for i in range (3 )]sum (weighted_choice_attentions)True )1 , :, -1 ]32 ,33 )[:, :-1 ] == 1 ] = 0 sum (dim=(0 ,1 )) / (1056 - mask_tensor.sum ())).float ().cpu().numpy()sum () for i in range (3 )]sum (weighted_choice_unused_attentions)"Instructed" : np.mean(instructed_attn), "Used" : np.mean(used_attn), "Ununsed" : np.mean(unused_attn)}"index" )
100%|██████████| 2/2 [00:19<00:00, 9.96s/it]
Instructed Used Ununsed
verb_v_adjective_3 0.345372 0.426140 0.379153
adjective_v_verb_3 0.408563 0.462195 0.483597
评估中英互译任务,指标为 PPL 困惑度:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 "en" , "zh" ]"ar" : "Arabic" , "fr" : "French" , "es" : "Spanish" , "de" : "German" , "en" : "English" , "ru" : "Russian" , "zh" : "Chinese" }"dataset/XNLI-15way/xnli.15way.orig.tsv" , sep='\t' ).select_columns(LANG_LIST)range (len (dataset) - 100 , len (dataset)))def eval_xnli_ppl (use_random, use_instruction ):for src_lang, tgt_lang in tqdm(list (itertools.permutations(LANG_LIST, 2 ))):f"{src_lang} _{tgt_lang} " ].sigmoid() >= 0.5 ).float ().numpy()if use_random:bool )1 ) * n_layers, n_heads + 1 )] = True map (lambda sample: {"input_str" : sample[src_lang] + f"\n\nTranslate into {LANG_DICT[tgt_lang]} :" if use_instruction else sample[src_lang],"target_str" : sample[tgt_lang]"input_str" , "target_str" ])if src_lang not in langs_original_ppl:0 }if src_lang not in langs_weighted_ppl:0 }for input_str, target_str in zip (*dev_dataset[:100 ].values()):format (src=input_str.strip()) + f"{target_str.strip()} <|eot_id|>" 2048 , truncation=True , padding=False , add_special_tokens=False , return_tensors="pt" ).to(DEVICE)format (src=input_str.strip()), add_special_tokens=False , return_tensors="pt" )["input_ids" ].size(-1 )"input_ids" ]).to(DEVICE)100 with torch.no_grad():0 ).repeat(1 , 1 ).to(model.device)"index" )print ("w/o head mask:" )"index" )print ("w/ head mask:" )print ("使用指令" )False , use_instruction=True )print ("使用指令,随机Mask" )True , use_instruction=True )print ("不使用指令" )False , use_instruction=False )print ("不使用指令,随机Mask" )True , use_instruction=False )
使用指令
100%|██████████| 2/2 [00:13<00:00, 6.62s/it]
w/o head mask:
en zh
en 0.000000 1.091267
zh 1.002608 0.000000
w/ head mask:
en zh
en 0.000000 1.004982
zh 0.986755 0.000000
使用指令,随机Mask
100%|██████████| 2/2 [00:13<00:00, 6.61s/it]
w/o head mask:
en zh
en 0.000000 1.091267
zh 1.002608 0.000000
w/ head mask:
en zh
en 0.000000 1.802226
zh 1.260897 0.000000
不使用指令
100%|██████████| 2/2 [00:13<00:00, 6.61s/it]
w/o head mask:
en zh
en 0.000000 2.643437
zh 2.142624 0.000000
w/ head mask:
en zh
en 0.000000 0.99274
zh 0.989524 0.00000
不使用指令,随机Mask
100%|██████████| 2/2 [00:13<00:00, 6.60s/it]
w/o head mask:
en zh
en 0.000000 2.643437
zh 2.142624 0.000000
w/ head mask:
en zh
en 0.000000 3.069456
zh 2.092448 0.000000
评估中英互译任务,指标为 ROUGE-L:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 "../model/bge-reranker-v2-m3" , use_fast=True )"rougeL" ], use_stemmer=True , tokenizer=sentence_tokenizer) def eval_xnli_rouge (use_instruction ):for src_lang, tgt_lang in tqdm(list (itertools.permutations(LANG_LIST, 2 ))[:12 ]): f"{src_lang} _{tgt_lang} " ].sigmoid() >= 0.5 ).float ().numpy()map (lambda sample: {"input_str" : sample[src_lang] + f"\n\nTranslate into {LANG_DICT[tgt_lang]} :" if use_instruction else sample[src_lang],"target_str" : sample[tgt_lang]"input_str" , "target_str" ])if src_lang not in langs_original_rouge:0 }if src_lang not in langs_weighted_rouge:0 }for input_str, target_str in zip (*dev_dataset[:100 ].values()):format (src=input_str.strip())2048 , truncation=True , padding=False , add_special_tokens=False ,return_tensors="pt" ).to(DEVICE)with torch.no_grad():50 , weight_tensor=None , do_sample=False )0 ][lm_inputs_src.input_ids.size(1 ):], skip_special_tokens=True ) "rougeL" ].fmeasure 0 ).repeat(1 , 1 ).to(model.device)50 , weight_tensor=mask_tensor, do_sample=False )0 ][lm_inputs_src.input_ids.size(1 ):], skip_special_tokens=True )"rougeL" ].fmeasure"index" )"index" )print ("使用指令" )True )print ("不使用指令" )False )
使用指令
100%|██████████| 2/2 [02:58<00:00, 89.34s/it]
en zh
en 0.000000 0.539153
zh 0.668623 0.000000
en zh
en 0.000000 0.60087
zh 0.654566 0.00000
不使用指令
100%|██████████| 2/2 [05:00<00:00, 150.44s/it]
en zh
en 0.00000 0.019667
zh 0.02056 0.000000
en zh
en 0.000000 0.603147
zh 0.655537 0.000000
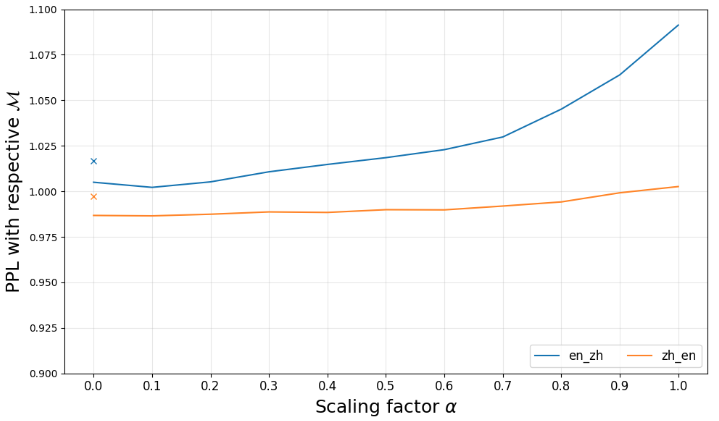
功能性注意力头消融实验:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 langs_weighted_ppl = {}"en" , "zh" ), ("zh" , "en" )]for src_lang, tgt_lang in tqdm(lang_pairs):map (lambda sample: {"input_str" : sample[src_lang] + f"\n\nTranslate into {LANG_DICT[tgt_lang]} :" ,"target_str" : sample[tgt_lang],"input_str" , "target_str" ])for v in np.arange(0 , 1.1 , 0.1 )}for input_str, target_str in tqdm(zip (*dev_dataset[:100 ].values()), total=100 ):format (src=input_str.strip()) + f"{target_str.strip()} <|eot_id|>" 2048 , truncation=True , padding=False , add_special_tokens=False ,return_tensors="pt" ).to(DEVICE)format (src=input_str.strip()), add_special_tokens=False , return_tensors="pt" )["input_ids" ].size(-1 )"input_ids" ]).to(DEVICE)100 with torch.no_grad():for min_weight in np.arange(0 , 1.1 , 0.1 ): f"{src_lang} _{tgt_lang} " ].sigmoid() >= 0.5 ).float ().numpy().clip(min =min_weight) 0 ).repeat(1 , 1 ).to(model.device)for k in weighted_ppl} f"{src_lang} _{tgt_lang} " ] = weighted_ppl"index" )
0%| | 0/2 [00:00<?, ?it/s]
100%|██████████| 100/100 [00:38<00:00, 2.61it/s]
50%|█████ | 1/2 [00:38<00:38, 38.36s/it]
100%|██████████| 100/100 [00:38<00:00, 2.62it/s]
100%|██████████| 2/2 [01:16<00:00, 38.25s/it]
0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
en_zh 1.004982 1.002170 1.005190 1.010720 1.014762 1.018487 1.022877 1.029847 1.045129 1.063954 1.091267
zh_en 0.986755 0.986517 0.987423 0.988694 0.988407 0.989914 0.989815 0.991908 0.994180 0.999186 1.002608
绘制消融实验图:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 colors = sns.color_palette(n_colors=2 ) 10 , 6 )) 0.9 , 1.1 ) 0 , 1.1 , 0.1 ), fontsize=12 ) r"Scaling factor $\alpha$" , fontsize=18 )r"PPL with respective $\mathcal{M}$" , fontsize=18 )"en_zh" : 1.016755 , "zh_en" : 0.997446 } for i, (lang_pair, values) in enumerate (df.iterrows()):0 , 1.1 , 0.1 ), values, linestyle='-' , label=lang_pair, c=colors[i])0 , maskonly_ppl[lang_pair], marker="x" , c=colors[i])0.3 ) 3 , fontsize=12 , loc="lower right" )
评估中英互译任务,指标为 BLEU,数据集为 IWSLT2017:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 LANG_DICT = {"fr" : "French" , "de" : "German" , "en" : "English" , "zh" : "Chinese" }"en_de" : 0.3 , "en_fr" : 0.2 , "en_zh" : 0.1 , "zh_en" : 0.3 , "fr_en" : 0.2 , "de_en" : 0.4 }def general_postprocess (text ):"\n\n" )if len (answer_text) > 2 :1 :2 ]elif len (answer_text) > 1 :1 :]"\n\n" .join(answer_text)r'[^\w\s]' , '' , answer_text) r'\s+' , ' ' , no_punctuation).strip() " " .join(jieba.cut(cleaned_text)) return cleaned_textdef postprocess_and_score (text, target_str ):"\n\n" )" " .join(jieba.cut(re.sub(r'\s+' , ' ' , re.sub(r'[^\w\s]' , '' , t)).strip())) for t in answer_text] for t in cleaned_texts] return max (zip (cleaned_texts, scores), key=lambda x: x[1 ]) for src_lang, tgt_lang in [("en" , "zh" ), ("zh" , "en" )]:if tgt_lang != "en" :f"dataset/iwslt2017/{src_lang} -{tgt_lang} -test.parquet" )else :f"dataset/iwslt2017/{tgt_lang} -{src_lang} -test.parquet" )map (lambda sample: {"input_str" : f"{sample['translation' ][src_lang]} \n\nTranslate into {tgt_lang} :" ,"target_str" : sample['translation' ][tgt_lang],"input_str" , "target_str" ])range (len (dataset) - 100 , len (dataset)))f"{src_lang} _{tgt_lang} " ].sigmoid() >= 0.5 ).float ().numpy().clip(min =LANGPAIR_MIN[f"{src_lang} _{tgt_lang} " ])for sample in tqdm(dev_dataset):"input_str" ], sample["target_str" ]format (src=input_str.strip())2048 , truncation=True , padding=False , add_special_tokens=False ,return_tensors="pt" ).to(DEVICE)with torch.no_grad():50 , weight_tensor=None , do_sample=False )0 ][lm_inputs_src.input_ids.size(1 ):], skip_special_tokens=True )0 ).repeat(1 , 1 ).to(model.device)50 , weight_tensor=mask_tensor, do_sample=False )0 ][lm_inputs_src.input_ids.size(1 ):], skip_special_tokens=True )f"{src_lang} _{tgt_lang} " ] = np.nanmean(original_bleu)f"{src_lang} _{tgt_lang} " ] = np.nanmean(weighted_bleu)print (f"{src_lang} _{tgt_lang} : {np.nanmean(original_bleu)} {np.nanmean(weighted_bleu)} " )"index" )"index" )
Loading model from cache /tmp/jieba.cache
Loading model cost 0.598 seconds.
Prefix dict has been built successfully.
100%|██████████| 100/100 [02:09<00:00, 1.30s/it]
en_zh: 0.3118341977481546 0.3301332102535084
100%|██████████| 100/100 [01:50<00:00, 1.10s/it]
zh_en: 0.5805953950107409 0.5813078377389967
0
en_zh 0.311834
zh_en 0.580595
0
en_zh 0.330133
zh_en 0.581308
2.3 研究
对比有指令和无指令的机器翻译结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 def translate (input_str, src_lang="en" , tgt_lang="zh" ):f"{src_lang} _{tgt_lang} " ].sigmoid() >= 0.5 ).float ().numpy().clip(min =0.0 )print (mask_weight.sum ())with torch.no_grad():format (src=input_str)+"" ], add_special_tokens=False , return_tensors="pt" ).to(DEVICE)50 , weight_tensor=None , do_sample=False )0 ][lm_inputs_src.input_ids.size(1 ):], skip_special_tokens=True )print ("[ORIGINAL]" , pred_str)0 ).repeat(1 , 1 ).to(model.device)50 , weight_tensor=mask_tensor, do_sample=False )0 ][lm_inputs_src.input_ids.size(1 ):], skip_special_tokens=True )print (f"[{tgt_lang} ]" , pred_str)len (mask_weight))].unsqueeze(0 ).repeat(1 , 1 ).to(model.device) 50 , weight_tensor=random_tensor, do_sample=False )0 ][lm_inputs_src.input_ids.size(1 ):], skip_special_tokens=True )print ("[RANDOM]" , pred_str)"I have never seen such a beautiful sunset." )"This is expected as the model has lost the majority of its attention heads.\n\nTranslate into Chinese:" )
856.0
[ORIGINAL] I'm glad you're enjoying the moment! Sunsets can be truly breathtaking, with their vibrant colors and serene atmosphere. They have a way of evoking feelings of peace and wonder. What made this sunset particularly special to you? Was it the colors
[zh] 我从来没有见过如此美丽的日落。
[RANDOM] As a conversational AI, I don't have personal experiences, but I can tell you that sunsets can be truly breathtaking. The colors of the sky during a sunset are a result of a combination of atmospheric conditions, including the scattering of light,
856.0
[ORIGINAL] 这也算是预期的,因为模型已经失去了大多数注意力头。
[zh] 这预计是因为模型失去了大多数注意力头。
[RANDOM] This is expected as the model has lost the majority of its attention.
计算每层的输出的平均相似度和前 5 个预测的 token:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 src_lang = "en" "zh" "I see a llama sleeping in my backyard." "\n\nTranslate into Chinese:" "我看见一只羊驼在我的后院睡觉。" with torch.no_grad():format (src=input_str_inst)+"" ], add_special_tokens=False , return_tensors="pt" ).to(DEVICE)format (src=input_str)+"" ], add_special_tokens=False , return_tensors="pt" ).to(DEVICE)True , output_attentions=True )0 , -1 ]) 1 )) 1 , descending=True )[:, k]) for k in range (5 )] 1 :, 0 , -1 ] - layer_outputs[:-1 , 0 , -1 ] "en_zh" ].sigmoid() >= 0.5 ).float ().numpy()).unsqueeze(0 ).repeat(1 , 1 ).to(model.device)True , output_attentions=True )0 , -1 ])1 ))1 , descending=True )[:, k]) for k in range (5 )]1 :, 0 , -1 ] - weighted_layer_outputs[:-1 , 0 , -1 ]print ("hidden similarity\n" , torch.cosine_similarity((layer_outputs[:, 0 , -1 ]), (weighted_layer_outputs[:, 0 , -1 ]))) print ("lm_head logits similarity\n" , torch.cosine_similarity(layer_token_logits, weighted_layer_token_logits)) print ("residual similarity\n" , torch.cosine_similarity((layer_outputs[1 :, 0 , -1 ] - layer_outputs[:-1 , 0 , -1 ]), (weighted_layer_outputs[1 :, 0 , -1 ] - weighted_layer_outputs[:-1 , 0 , -1 ]))) "display.max_colwidth" , None ) "display.max_rows" , None ) "original" : original_layer_pred_tokens, "weighted" : weighted_layer_pred_tokens})
hidden similarity
tensor([1.0000, 0.7852, 0.7617, 0.7852, 0.7422, 0.7539, 0.7266, 0.7422, 0.6875,
0.5859, 0.5508, 0.5859, 0.5195, 0.5430, 0.4531, 0.5117, 0.5938, 0.6406,
0.7109, 0.7383, 0.7383, 0.7656, 0.7930, 0.8125, 0.8242, 0.8438, 0.8477,
0.8477, 0.8438, 0.8359, 0.8320, 0.8125, 0.7500], device='cuda:0',
dtype=torch.bfloat16)
lm_head logits similarity
tensor([1.0078, 0.7930, 0.7773, 0.8008, 0.7539, 0.8008, 0.8281, 0.8398, 0.7656,
0.6719, 0.6406, 0.7305, 0.7031, 0.5430, 0.4609, 0.5078, 0.6016, 0.6562,
0.8281, 0.8516, 0.9062, 0.9219, 0.9609, 0.9688, 0.9727, 0.9766, 0.9766,
0.9805, 0.9766, 0.9766, 0.9727, 0.9258, 0.7188], device='cuda:0',
dtype=torch.bfloat16)
residual similarity
tensor([0.7383, 0.6719, 0.6719, 0.5430, 0.6094, 0.5234, 0.5234, 0.4316, 0.2520,
0.2656, 0.2871, 0.2852, 0.2314, 0.2969, 0.3125, 0.3984, 0.4570, 0.6133,
0.5977, 0.6133, 0.7031, 0.7578, 0.7188, 0.7578, 0.8086, 0.7305, 0.7109,
0.7617, 0.7461, 0.7070, 0.7969, 0.7773], device='cuda:0',
dtype=torch.bfloat16)
0 1 2 3 4
0 illo abil incer otron câ
1 cheng the čin utas Alam
2 'gc alink utas .netbeans
3 'gc .netbeans -toggler cheng
4 'gc .netbeans reff .CR edn
5 'gc -toggler шиб ATAB \Dependency
6 #ab 'gc #ac kke ーニ
7 -*-\r\n #ad #ab .netbeans 'gc
8 LLU -LAST -*-\r\n 'gc #ab
9 emain 'gc #af ektor chalk
10 poil .SIG GetInt emain >tag
11 'gc >tag .SIG цес poil
12 ruz 감 корист ncy >tag
13 'gc корист pNet dime Sharper
14 'gc pNet .Reporting Sharper isci
15 -wsj � ContentLoaded меть pNet
16 -wsj >tag :uint lap hon
17 RetVal hon )frame -wsj Macy
18 hon artz increasingly confidently RetVal
19 confidently bes increasingly WSTR hon
20 bes hon increasingly (
21 hon bes in increasingly p
22 I my in c p
23 I my you c me
24 I you my in ..\n
25 my I ..\n in you
26 my ..\n in you I
27 my I ..\n in you
28 in my you ..\n …\n
29 …\n ..\n in /stdc backyard
30 …\n /stdc in ..\n _exempt
31 backyard _exempt 我 in ..\n
32 我 你 您 在 有
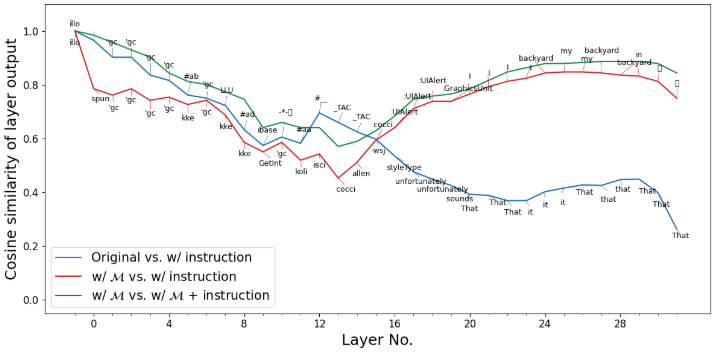
计算并绘制每层输出之间的平均相似度:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 with torch.no_grad():format (src=input_str_inst)+target_str], add_special_tokens=False , return_tensors="pt" ).to(DEVICE)format (src=input_str)+target_str], add_special_tokens=False , return_tensors="pt" ).to(DEVICE)"en_zh" ].sigmoid() >= 0.5 ).float ().numpy()).unsqueeze(0 ).repeat(1 , 1 ).to(model.device)True , output_attentions=True )0 , -15 ].argmax(-1 )) True , output_attentions=True )0 , -15 ].argmax(-1 ))True , output_attentions=True )0 , -15 ].argmax(-1 ))True , output_attentions=True )0 , -15 ].argmax(-1 ))0 , -15 :-14 ].mean(dim=-2 )), (weighted_layer_outputs[:, 0 , -15 :-14 ].mean(dim=-2 ))).float ().cpu().numpy()0 , -15 :-14 ].mean(dim=-2 )), (layer_outputs[:, 0 , -15 :-14 ].mean(dim=-2 ))).float ().cpu().numpy()0 , -15 :-14 ].mean(dim=-2 )), (weighted_inst_layer_outputs[:, 0 , -15 :-14 ].mean(dim=-2 ))).float ().cpu().numpy()print ("Similarity between w/ mask vs. w/ instruction\n" , cosine_sim1) print ("Similarity between Original vs. w/ instruction\n" , cosine_sim2) print ("Similarity between w/ mask vs. w/ mask + instruction\n" , cosine_sim3) "Blues" , 3 ), sns.color_palette("Reds" , 3 ), sns.color_palette("Greens" , 3 ) 12 , 6 ))"Layer No." , fontsize=18 )1 , 32 , 4 ), labels=np.arange(0 , 32 , 4 ), fontsize=12 )33 ), minor=True )"Cosine similarity of layer output" , fontsize=18 )12 )"Original vs. w/ instruction" , c=b2)r"w/ $\mathcal{M}$ vs. w/ instruction" , c=r2)r"w/ $\mathcal{M}$ vs. w/ $\mathcal{M}$ + instruction" , c=g2)for i, (xi, yi1, yi2, yi3) in enumerate (zip (np.arange(33 ), cosine_sim1, cosine_sim2, cosine_sim3)):0.05 if xi<16 else yi1+0.05 , weighted_layer_pred_tokens[i], fontsize=9 , ha="center" )) 0.05 if xi<16 else yi2-0.05 , layer_pred_tokens[i], fontsize=9 , ha="center" )) False ) for (t1, t2), xi, yi1, yi2 in zip ([(texts[i], texts[i+1 ]) for i in range (0 , len (texts), 2 )], np.arange(33 ), cosine_sim1, cosine_sim2):0.02 if xi<16 else yi1+0.04 ], color=r2, linestyle="-" , linewidth=0.5 )0.02 if xi<16 else yi2-0.02 ], color=b2, linestyle="-" , linewidth=0.5 )0.05 , 1.1 )15 )
Similarity between w/ mask vs. w/ instruction
[1. 0.78515625 0.76171875 0.78515625 0.7421875 0.75390625
0.7265625 0.7421875 0.6875 0.5859375 0.55078125 0.5859375
0.51953125 0.54296875 0.453125 0.51171875 0.59375 0.640625
0.7109375 0.73828125 0.73828125 0.765625 0.79296875 0.8125
0.82421875 0.84375 0.84765625 0.84765625 0.84375 0.8359375
0.83203125 0.8125 0.75 ]
Similarity between Original vs. w/ instruction
[1. 0.96484375 0.90234375 0.90234375 0.8359375 0.81640625
0.76171875 0.75 0.72265625 0.6328125 0.57421875 0.60546875
0.58203125 0.6953125 0.66015625 0.625 0.59765625 0.53515625
0.4765625 0.44921875 0.42578125 0.39257812 0.38867188 0.36914062
0.36914062 0.40234375 0.41601562 0.42773438 0.42578125 0.44726562
0.44921875 0.3984375 0.26367188]
Similarity between w/ mask vs. w/ mask + instruction
[1. 0.984375 0.95703125 0.9296875 0.90234375 0.84375
0.8125 0.80078125 0.7734375 0.74609375 0.640625 0.66015625
0.640625 0.640625 0.5703125 0.58984375 0.62890625 0.68359375
0.74609375 0.7578125 0.765625 0.78515625 0.81640625 0.84765625
0.86328125 0.87890625 0.87890625 0.8828125 0.88671875 0.88671875
0.88671875 0.87890625 0.84375 ]
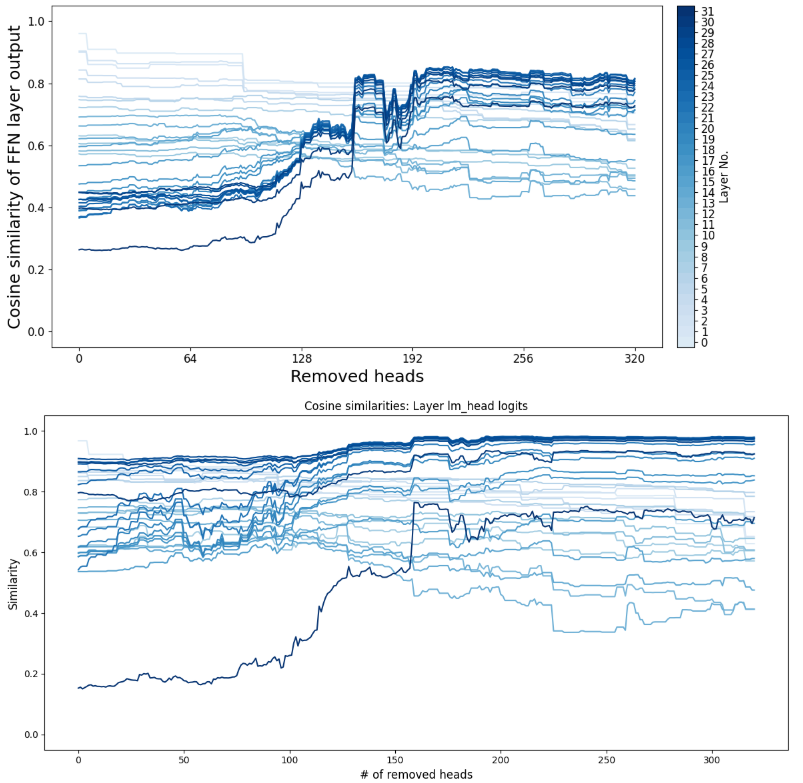
逐步移除功能性注意力头后计算每层输出的平均相似度:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 with torch.no_grad():format (src=input_str_inst)], add_special_tokens=False , return_tensors="pt" ).to(DEVICE)format (src=input_str)], add_special_tokens=False , return_tensors="pt" ).to(DEVICE)True , output_attentions=True )0 , -1 ]).float ().cpu()"en_zh" ].sigmoid().numpy()32 ::33 ] = 0 32 :] "en_zh" ].sigmoid().numpy())0 ).repeat(1 , 1 ).to(model.device)320 ]with torch.no_grad():True , output_attentions=True )0 , -1 ])0 , -1 ].float ().cpu())float ().cpu())for head_idx in tqdm(test_order):0 , head_idx] = 0 with torch.no_grad():True , output_attentions=True )0 , -1 ])0 , -1 ].float ().cpu())float ().cpu())32 )"Blues" , n_colors=36 )[-32 :] 12 , 6 ))"Removed heads" , fontsize=18 )0 , 1025 , 64 ), labels=np.arange(0 , 1025 , 64 ), fontsize=12 )"Cosine similarity of FFN layer output" , fontsize=18 )12 )0.05 , 1.05 )1 , 0 , -1 ].squeeze(0 ).float ().cpu(), weighted_outputs[:, l+1 ]).float ().cpu().numpy() for l in range (len (layers))]for l in layers:f"Layer {l} " )0 , vmax=32 )"vertical" , pad=0.02 )"Layer No." , fontsize=12 )0 , 32 )+0.5 )0 , 32 ), fontsize=12 )12 )12 , 6 ))"# of removed heads" , fontsize=12 )"Similarity" , fontsize=12 )for l in layers:1 ].squeeze(0 ).float ().cpu(), weighted_logits[:, l+1 ]).float ().cpu().numpy(), c=colors[l], label=f"Layer {l} " )0.05 , 1.05 )"Cosine similarities: Layer lm_head logits" )
100%|██████████| 320/320 [01:15<00:00, 4.24it/s]
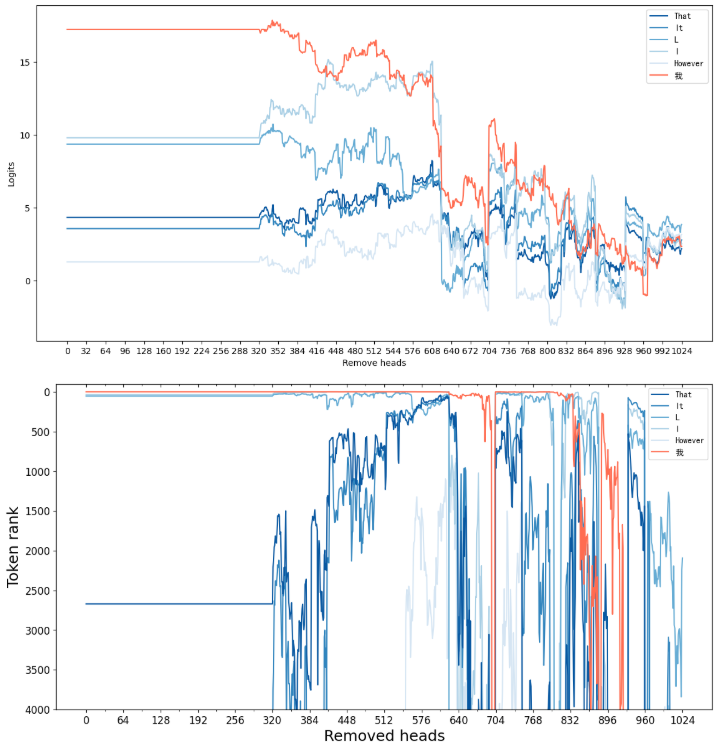
跟踪特定 token 的 logits 值和排名如何随着注意力头的逐步移除而变化:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 lm_inputs_src = tokenizer([LLAMA_TEMPLATE.format (src=input_str)], add_special_tokens=False , return_tensors="pt" ).to(DEVICE)0 , -1 ].detach().cpu().numpy()1 ][:5 ]True ) for token_id in topk_token_ids]"我" , add_special_tokens=False )[0 ] with torch.no_grad():20 , weight_tensor=test_tensor, do_sample=False )0 ][lm_inputs_src.input_ids.size(1 ):], skip_special_tokens=True )"all.csv" , encoding="utf-8" )0 , -1 ].cpu().numpy() 1 ].argsort()[topk_token_ids].tolist() + [weighted_output_logits.argsort()[::-1 ].argsort()[query_token_id]])) for head_idx in tqdm(test_order):0 , head_idx] = 0 with torch.no_grad():20 , weight_tensor=test_tensor, do_sample=False )0 ][lm_inputs_src.input_ids.size(1 ):], skip_special_tokens=True )"remove.csv" , encoding="utf-8" )0 , -1 ].cpu().numpy()1 ].argsort()[topk_token_ids].tolist() + [weighted_output_logits.argsort()[::-1 ].argsort()[query_token_id]]))
100%|██████████| 1024/1024 [18:31<00:00, 1.08s/it]
进行重排序消融实验:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 1 :, -1 ] - pred_rank[:-1 , -1 ])320 ].argsort()[::-1 ]for head_idx in tqdm(rerank_test_order):0 , head_idx] = 0 with torch.no_grad():20 , weight_tensor=test_tensor, do_sample=False )0 ][lm_inputs_src.input_ids.size(1 ):], skip_special_tokens=True )"test.csv" , encoding="utf-8" )0 , -1 ].cpu().numpy()1 ].argsort()[topk_token_ids].tolist() + [weighted_output_logits.argsort()[::-1 ].argsort()[query_token_id]]))
100%|██████████| 320/320 [06:43<00:00, 1.26s/it]
可视化结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 "Blues" , 5 )[::-1 ]"Reds" , 1 )[-1 ]14 , 7 ))for i in range (6 ):if i < 5 :else :"我" , color=red)"Remove heads" )"Logits" )range (0 , 1025 , 32 ))14 , 7 ))for i in [4 ,3 ,2 ,1 ,0 ,5 ]:if i < 5 :else :"我" , color=red)"Removed heads" , fontsize=18 )"Token rank" , fontsize=18 )0 , 1025 , 64 ), labels=np.arange(0 , 1025 , 64 ), fontsize=12 )32 , 1025 , 64 ), minor=True )0 , 4001 , 500 ), labels=np.arange(0 , 4001 , 500 ), fontsize=12 )100 , 4000 )"in" , which="both" )0 , 1025 , 64 ), labels=[])32 , 1025 , 64 ), minor=True )for i in [4 ,3 ,2 ,1 ,0 ,5 ]], [topk_tokens[i] for i in range (5 )] + ["我" ], fontsize=12 )
查看检查点结果:
1 2 3 4 5 6 7 8 9 step_weight_dict = {}for root, dir , files in os.walk("output/llama/xnli/en_zh" ):for file in files:if file.endswith(".safetensors" ):int (os.path.basename(root).split("-" )[-1 ])"tensor" ]dict (sorted (step_weight_dict.items()))len (step_weight_dict)
200
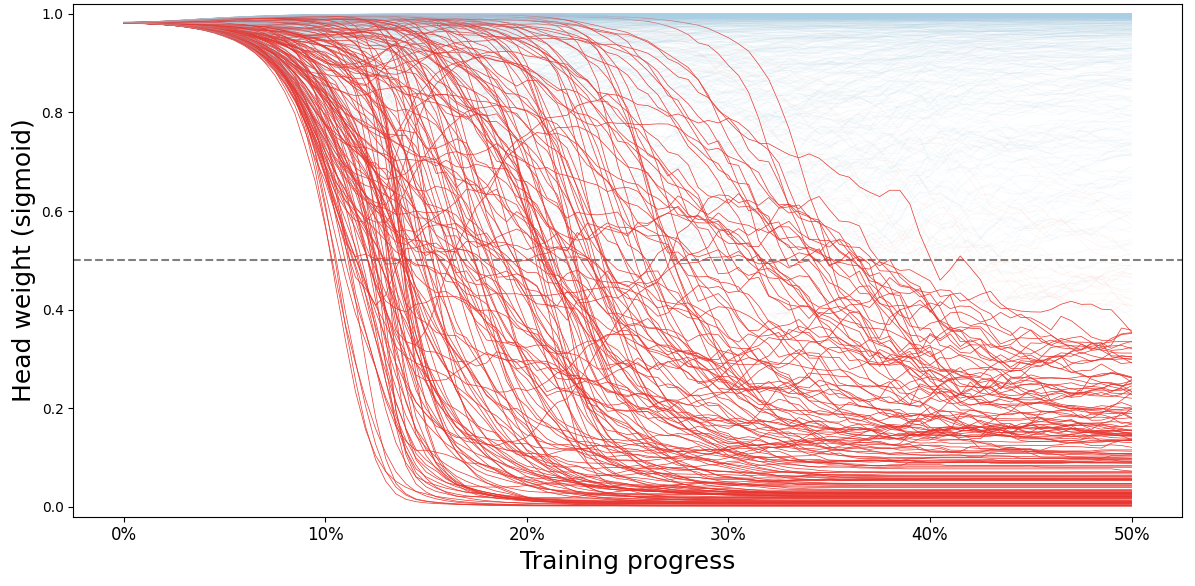
可视化注意力头激活情况:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 (b1, b2), (r1, r2) = sns.color_palette("Blues" , 2 ), sns.color_palette("Reds" , 2 )32 , 33 )[:, :-1 ].flatten().sigmoid() for t in step_weight_dict.values()]).numpy()12 , 6 ))0.5 , color="gray" , linestyle="--" )for i in range (1024 ):if (step_weight_array[:100 , i] < 0.5 ).all () or (step_weight_array[-1 , i] >= 0.5 and (step_weight_array[:60 , i] >= 0.5 ).any ()) or (0.3 < step_weight_array[-1 , i] <= 0.7 ):if step_weight_array[-1 , i] >= 0.5 else r1range (101 ), step_weight_array[:101 , i], linewidth=0.5 , alpha=0.1 , color=c)else :if step_weight_array[-1 , i] >= 0.5 else r2range (101 ), step_weight_array[:101 , i], linewidth=0.5 , alpha=1 , color=c)"Training progress" , fontsize=18 )0 , 101 , 20 ), labels=["0%" , "10%" , "20%" , "30%" , "40%" , "50%" ], fontsize=12 )"Head weight (sigmoid)" , fontsize=18 )0.02 , 1.02 )